1、Selenium入门 入门安装参考网页:Python selenium 库 | 菜鸟教程 (runoob.com) 。
# pip安装selenium pip install selenium # 查看selenium版本 pip show selenium
Selenium 需要WebDriver 与浏览器进行交互,实现对浏览器的控制。WebDriver是Selenium的核心组件之一,它提供了简单又强大的API,允许多种开发语言使用webdriver来操作多种浏览器。
不同的浏览器需要不同的 WebDriver,根据需要下载相应的 WebDriver ,并在系统 PATH 中添加WebDriver的路径。
笔者用的是Edge,相应的WebDriver下载路径在此:Microsoft Edge WebDriver | Microsoft Edge Developer ,选择对应的系统版本。
可以下载后的文件解压在D盘的文件夹内,如果用anaconda也可以把其中的.exe文件保存在anaconda的安装目录下。
打开【控制面板】-【系统和安全】-【系统】-【高级系统设置】-【环境变量】,在下面【系统变量】中,找到Path,点击【编辑】,然后点击【新建】,然后点击【浏览】,浏览到刚刚解压的目录,随后一路确认回去。
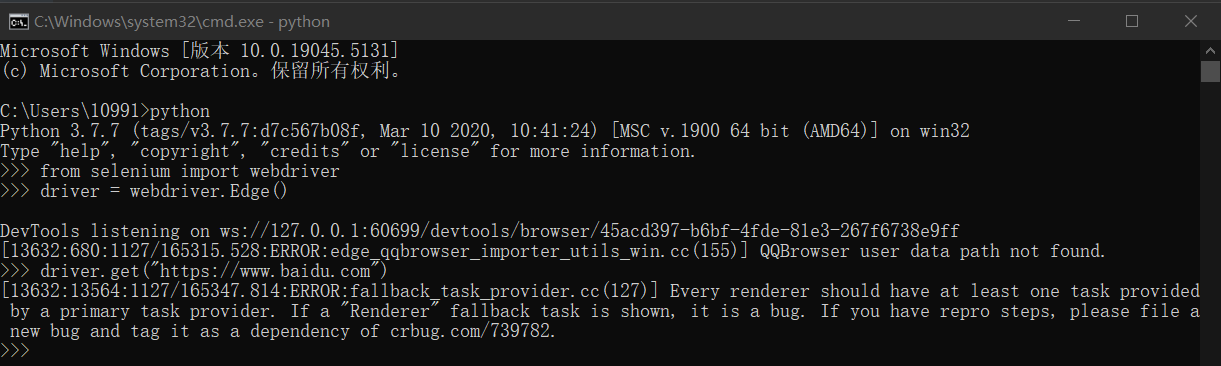
然后打开python的IDE窗口,输入下面代码,如果运行后弹出edge浏览器,则说明配置正确。
from selenium import webdriverfrom selenium.webdriver.edge.service import Serviceservice = Service(executable_path='/path/to/msedgedriver' ) options = webdriver.EdgeOptions() driver = webdriver.Edge(service=service, options=options)
Tips:可能会出现版本不兼容的问题,不过只要能打开浏览器,问题就不大。
然后我们尝试打开一个网页。
driver.get("https://www.baidu.com" )
此时可以看到edge中已经打开了百度搜索。
配置webdriver的代码可以进行标准化,我这里放上对于edge浏览器和chrome浏览器的版本,标准化的配置代码可以直接用于程序的开头。
from selenium import webdriver driver = webdriver.Edge() driver.get("https://www.baidu.com" )
from selenium import webdriver driver = webdriver.Chrome() driver.get("https://www.baidu.com" )
把以上代码放在cmd的python黑框框中运行(也可以放在IDE中),如果打开edge浏览器并打开百度的首页,则说明配置和创建WebDriver是成功的。
接下来是一些多余的测试代码,可以试试也可以掠过。
search_box = driver.find_element("id" , "kw" ) search_button = driver.find_element("class name" , "s_ipt" ) links = driver.find_elements("tag name" , "a" )
search_box.send_keys("Selenium Python" ) search_button.click()
element_text = search_box.text element_attribute = search_box.get_attribute("placeholder" ) driver.quit()
一些基础的selenium方法(看看就行,可以略过)。
方法
说明
示例代码
webdriver.Chrome()初始化 Chrome 浏览器实例。
driver = webdriver.Chrome()
driver.get(url)访问指定的 URL 地址。
driver.get("https://example.com")
driver.find_element(By.ID, "")按照ID查找。
element = driver.find_element(By.ID, "id")
driver.find_elements(By.CLASS_NAME, "")按照类名查找。
elements = driver.find_elements(By.CLASS_NAME, "class")
element.click()点击。
element.click()
element.send_keys(value)向输入框中发送特定内容。
element.send_keys("text")
element.text获取元素的文本内容。
text = element.text
driver.back()浏览器后退。
driver.back()
driver.forward()浏览器前进。
driver.forward()
driver.refresh()刷新当前页面。
driver.refresh()
driver.execute_script(script, *args)执行 JS 脚本
driver.execute_script("alert('Hello!')")
driver.switch_to.frame(frame_reference)切换到指定的 iframe。
driver.switch_to.frame("frame_id")
driver.switch_to.default_content()切换回主文档。
driver.switch_to.default_content()
driver.quit()关闭浏览器并退出
driver.quit()
driver.close()关闭当前窗口。
driver.close()
2、Selenium+Python实现爬虫的原理 我们在访问web网页时,页面数据会以http协议 来传输和展示。理论上,只要我们能在浏览器中看到的数据,都可以通过代码来捕获。
Selenium本质上是一个web自动化测试工具,可以模拟人的操作来访问网站 ,所以Selenium可以用在测试、抢票、爬虫、刷单等等。
用Selenium结合Python实现爬虫是十分巧妙的用途,优点是:1、不容易被反爬,2、思路简单,3、可以执行页面js脚本和复杂的登录等操作。缺点是:1、爬取速度慢,2、数据流量大,3、容易受网络环境影响。所以,用Selenium结合Python一般用于小规模数据的爬取,且数据获取相对简单 。
Selenium提供给我们各种操作网页的函数,包括点击、获取、输入、定位、切换、关闭 等。按照人访问的流程,所有利用Selenium爬虫的代码都大致按照如下流程:
1、配置webdrive ,确保selenium和浏览器能够进行交互;
2、打开目标数据所在的网页 ,一般会涉及点击、登录、切换页面、翻页等操作,其中翻页是比较困难的;
3、定位并爬取页面上的数据元素 ,这是重点和难点所在,后面会详细介绍;
4、保存数据 ,这里看重python基础,可以按照自己的需求把数据保存为exl等多种格式;
5、退出并关闭 ,释放内存。
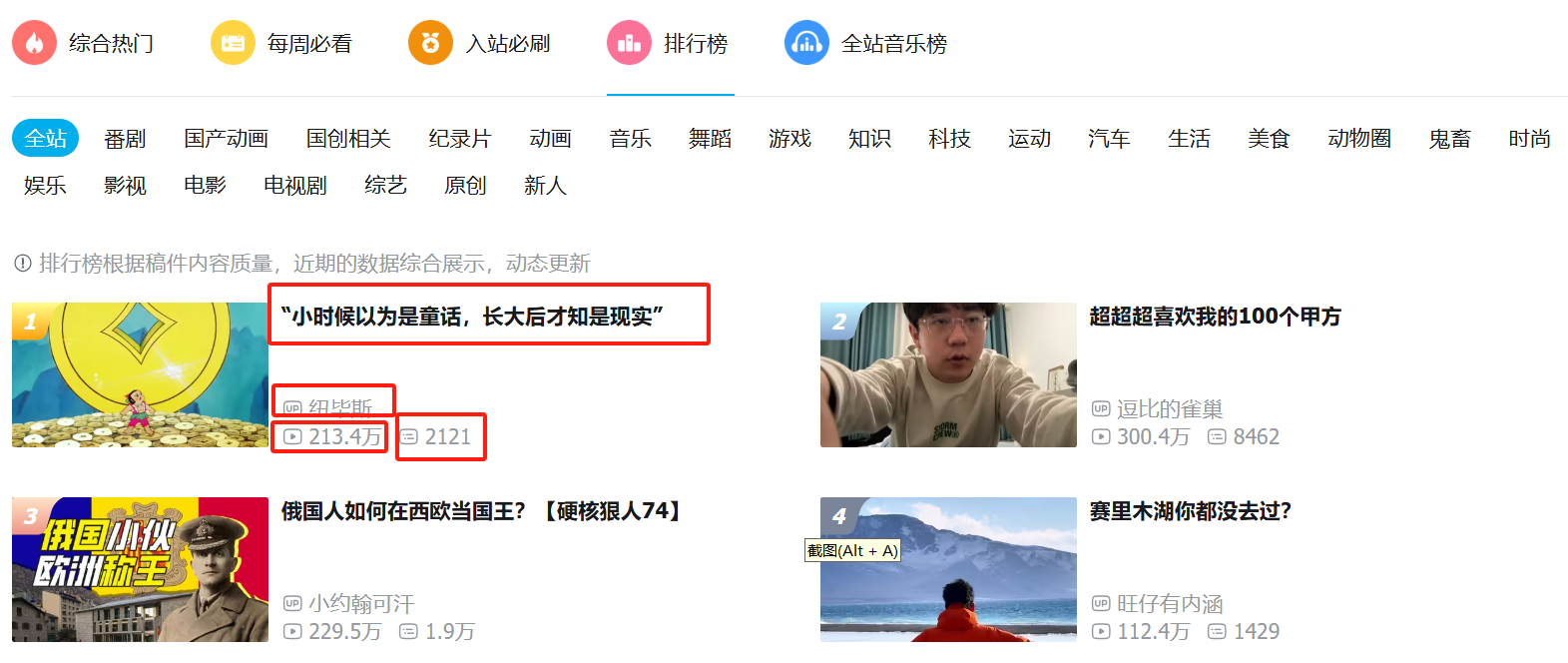
3、案例1:爬取B站热门视频排行榜的视频信息 3.1、任务需求 需求:爬取B站热门视频排行榜(只爬取全站排行),目标网址:哔哩哔哩排行榜 ,爬取内容:视频标题、up主、播放次数、评论数,具体如下图所示。
3.2、打开目标网页 完成”1、配置webdrive ,2、打开目标数据所在的网页 “的步骤是较为轻松的,具体代码如下(代码文件为bilibili.py)。
from selenium import webdriver driver = webdriver.Edge() driver.get("https://www.bilibili.com/v/popular/rank/all" )
笔者的第一次运行有提示:The msedgedriver version (131.0.2903.48) detected in PATH at E:\edgedriver_win64\msedgedriver.exe might not be compatible with the detected edge version (131.0.2903.48); currently, msedgedriver 131.0.2903.70 is recommended for edge 131.*, so it is advised to delete the driver in PATH and retry。这是因为Edge的WebDriver有更新,我去官网下载了最新版本的重新解压到了E盘(我的安装路径)中,就没再报错了。
正确的运行结果是return 0,并且直接退出。
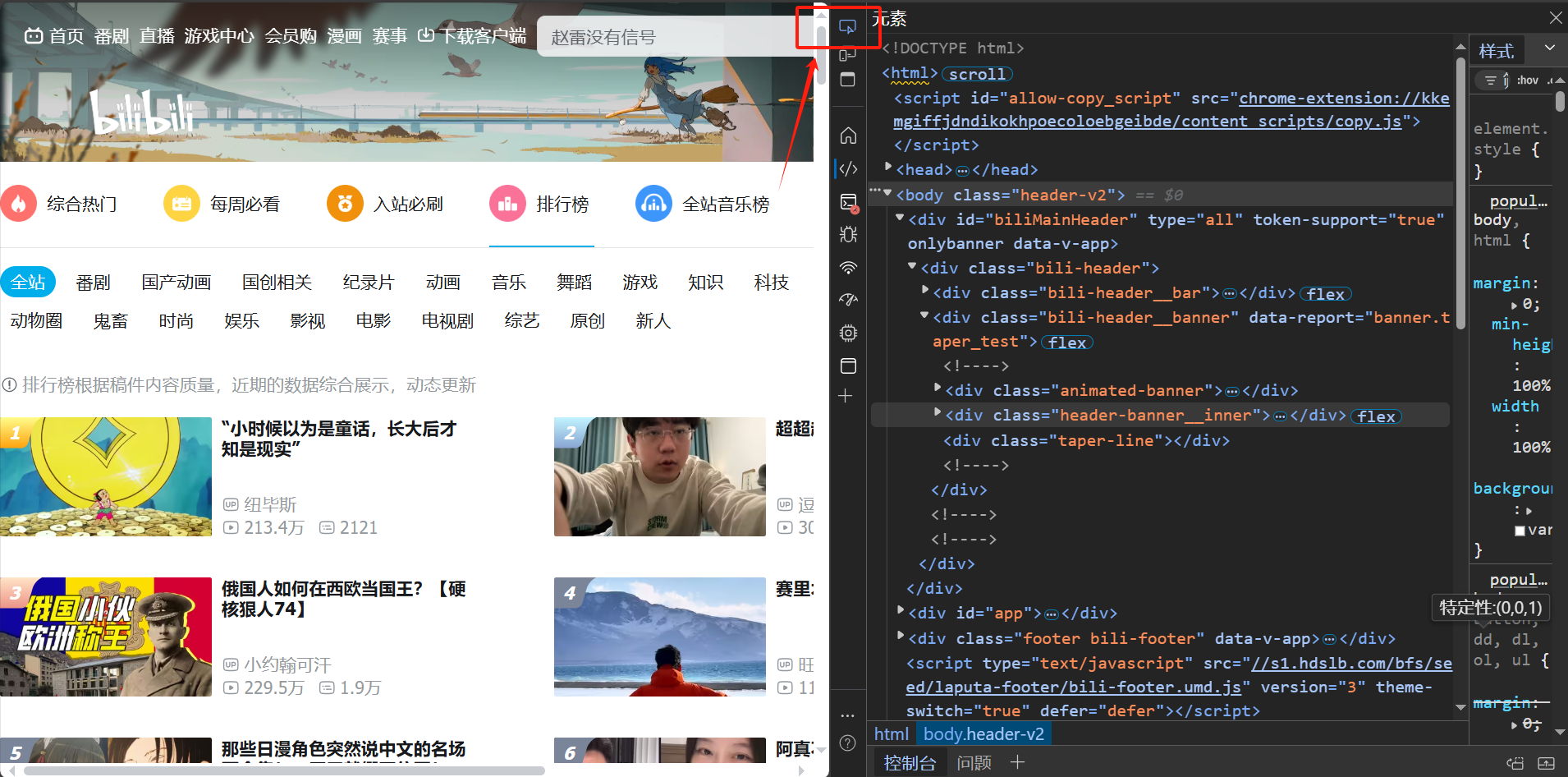
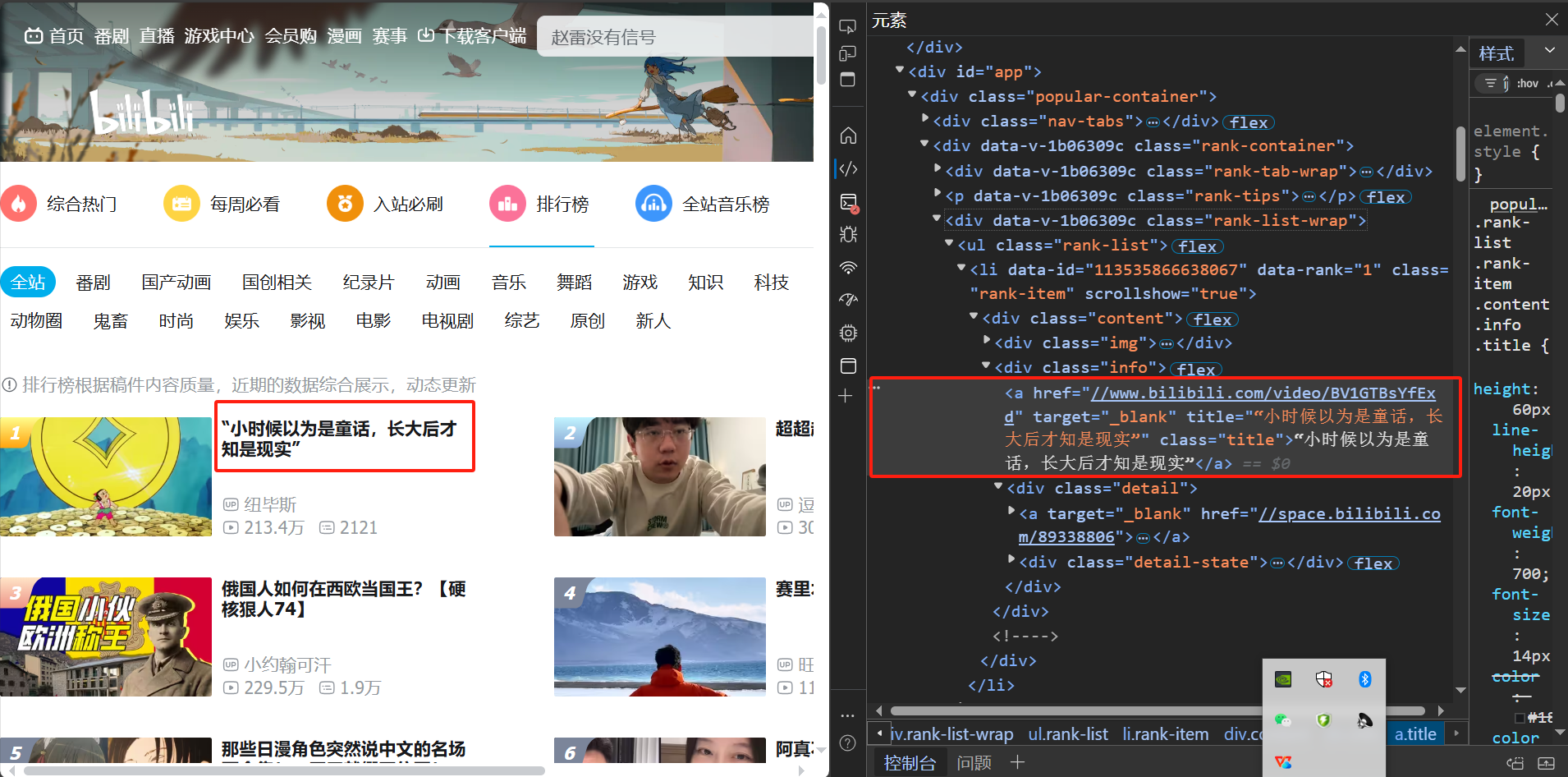
3.3、定位并爬取页面上的数据元素 1、捋清页面结构 下一步我们进行”3、定位页面上的数据元素 “,我们进入目标页面,按f12进入开发者模式,点击【选择元素】的图标,如下图所示,定位到我们的目标元素1-视频名。
可以看到,点击视频名时,右侧的红框区域亮起,这里就是我们标题名在html文件中的位置。
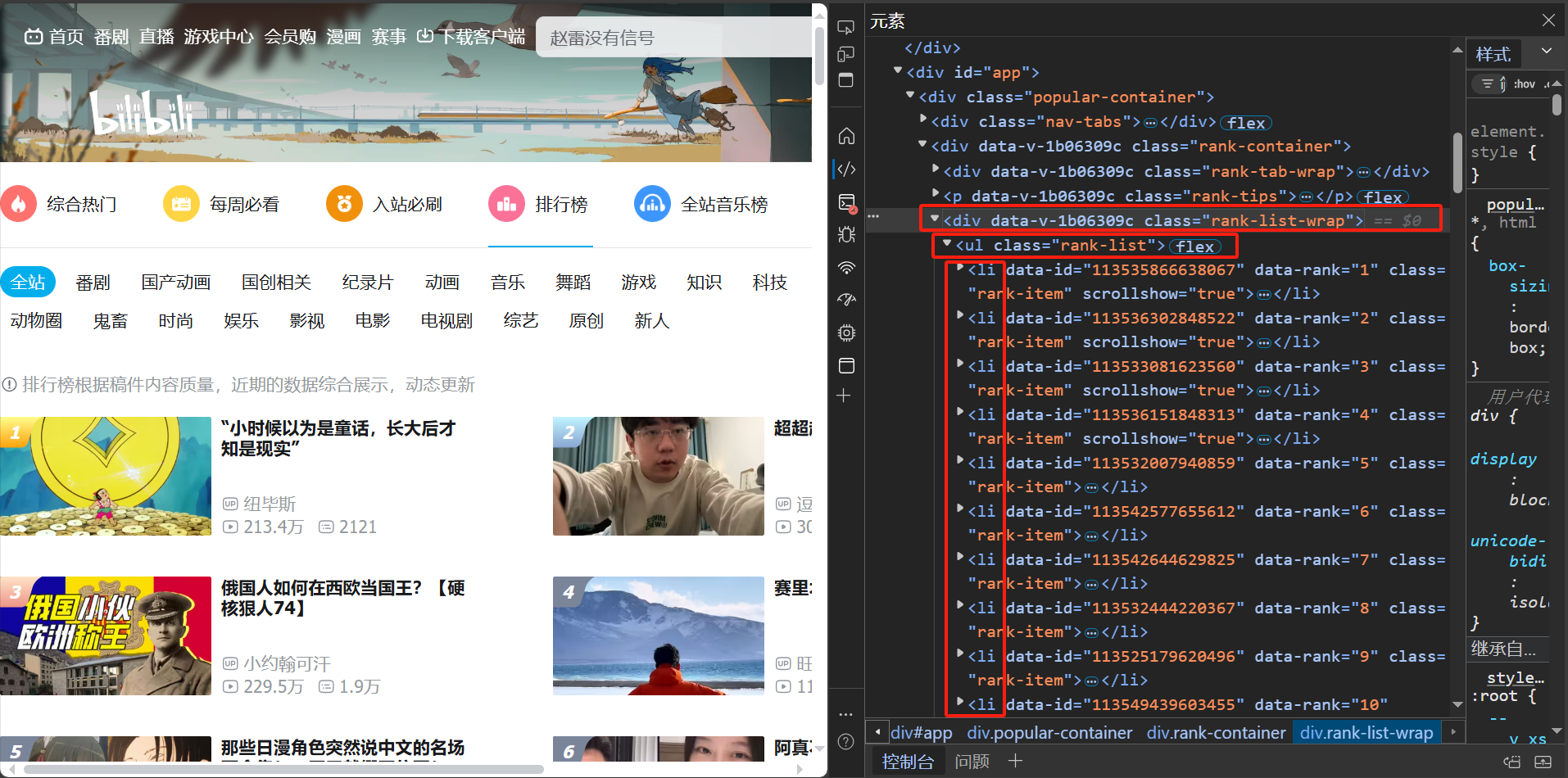
观察发现,所有的排行榜视频信息都在一个一个的<li></li>元素中,外面嵌套在了一个<ul></ul>和<div></div>中。具体如下图所示。
我们点击其中一个<li></li>,在右下角可以看到元素类型和class名的组合,我们可以通过这个提示入手,即查找当前网页上所有<li>标签且类名为rank-item的元素,并将这些元素存储在列表中。之后,遍历这个列表,对每个元素提取文本内容、获取属性等。
之后应该到在当前网页上查找所有<li>标签且类名为rank-item的元素。
2、定位第一层的<li>元素 WebDriver给我们提供了可以完成查找元素任务的函数**find_elements**,这里加了s,说明查找的不止一个,该函数返回一个列表。在selenium的官网上,我们可以看到该函数的用法。
但是我们现在要找的是所有<li>标签且类名为rank-item的元素,**'li.rank-item'**是一个CSS选择器字符串,我们应该使用CSS选择器来定位。
在Selenium WebDriver中,可以用By定位页面元素,By是位于selenium.webdriver.common.by模块中的一个类(方法),在使用之前我们要先import一下。
from selenium.webdriver.common.by import By
然后我们可以利用find_elements()函数,来查找所有li.rank-item元素,并保存在列表中。
video_items = driver.find_elements(By.CSS_SELECTOR, 'li.rank-item' )
为了测试,我们在打开网页之后加上这行代码,并print出来,看<li>元素是否已经存储在video_items列表中。
from selenium import webdriverfrom selenium.webdriver.common.by import By driver = webdriver.Edge() driver.get("https://www.bilibili.com/v/popular/rank/all" ) video_items = driver.find_elements(By.CSS_SELECTOR, 'li.rank-item' ) print (video_items)
可是此时如果直接打印,会看到这样的信息:<selenium.webdriver.remote.webelement.WebElement (session="...", element="...")> ...。
这是因为此时返回的是WebElement对象的字符串表示,这个字符串主要是为了提供一些基本信息,比如类型、会话ID和元素ID,而不是为了展示元素的内容或属性。
其中不同的区块解释如下:
1、selenium.webdriver.remote.webelement.WebElement:表示对象的类型,表明它是一个Selenium的WebElement对象。
2、session="...":这是与WebDriver服务器会话的唯一标识符。每个WebDriver实例在启动时都会与服务器建立一个会话,并且这个会话在整个测试生命周期中都是唯一的。
3、element="...":这是页面上实际HTML元素的唯一标识符。这个标识符是由WebDriver服务器生成的,用于在后续的命令中引用这个特定的元素。
我们需要加上.text才可以看到具体的文本内容。
first_item = video_items[0 ].text print (f"第一项是: {first_item} " )total_items = len (video_items) print (f"总项数是: {total_items} " )
运行结果如下:
E:\Selenium_Learning\Scripts\python.exe E:\Selenium_Learning\bilibili.py 第一项是: 1 《崩坏:星穹铁道》千星纪游PV:「太阳落下之后」 崩坏星穹铁道 288.3万 1.1万 总项数是: 100 进程已结束,退出代码0
3、在<li>元素中提取关键信息 之后我们可以按照文本的分割行来分割每一行,并对应上不同的内容,但是这样处理的容错率不高,如果哪一个视频缺少某一部分信息,就会出现错位。
现在我们已经定位并提取到了<li>元素,我们不妨看一下每一个<li>元素的原始html内容。
<li data-id ="113560092935193" data-rank ="1" class ="rank-item" scrollshow ="true" > <div class ="content" > <div class ="img" > <a href ="//www.bilibili.com/video/BV1ZBzhYREVs" target ="_blank" > <img class ="lazy-image cover" data-src ="..." src ="..." lazy ="loaded" > </a > <i class ="num num-1" > <svg viewBox ="0 0 41 30" fill ="none" xmlns ="..." class ="rank-icon" > <path fill-rule ="evenodd" clip-rule ="evenodd" d ="..." fill ="url(#rank-linear-1)" > </path > <defs > <linearGradient id ="rank-linear-1" x1 ="0" y1 ="0" x2 ="0" y2 ="30" gradientUnits ="userSpaceOnUse" > <stop class ="start" > </stop > <stop offset ="1" class ="end" > </stop > </linearGradient > </defs > </svg > <span > 1</span > </i > <div class ="w-later van-watchlater black" > <span class ="wl-tips" style ="display: none;" > </span > </div > </div > <div class ="info" > <a href ="//www.bilibili.com/video/BV1ZBzhYREVs" target ="_blank" title ="《崩坏:星穹铁道》千星纪游PV:「太阳落下之后」" class ="title" > 《崩坏:星穹铁道》千星纪游PV:「太阳落下之后」</a > <div class ="detail" > <a target ="_blank" href ="//space.bilibili.com/1340190821" > <span class ="data-box up-name" > <svg class ="data-box__icon" xmlns ="http://www.w3.org/2000/svg" xmlns:xlink ="http://www.w3.org/1999/xlink" viewBox ="0 0 18 18" width ="18" height ="18" style ="width: 18px; height: 18px;" > <path d ="M4 ..." fill ="currentColor" > </path > <path d ="M9 ..." fill ="currentColor" > </path > <path d ="M9 ..." fill ="currentColor" > </path > </svg > 崩坏星穹铁道 </span > </a > <div class ="detail-state" > <span class ="data-box" > <svg class ="data-box__icon" xmlns ="http://www.w3.org/2000/svg" xmlns:xlink ="http://www.w3.org/1999/xlink" viewBox ="0 0 18 18" width ="18" height ="18" style ="width: 18px; height: 18px;" > <path d ="M9 ..." fill ="currentColor" > </path > <path d ="M11 ..." fill ="currentColor" > </path > </svg > 288.1万 </span > <span class ="data-box" > <svg class ="data-box__icon" xmlns ="http://www.w3.org/2000/svg" xmlns:xlink ="http://www.w3.org/1999/xlink" viewBox ="0 0 18 18" width ="18" height ="18" style ="width: 18px; height: 18px;" > <path d ="M9 ..." fill ="currentColor" > </path > <path d ="M11 ..." fill ="currentColor" > </path > <path d ="M13 ..." fill ="currentColor" > </path > <path d ="M5 ..." fill ="currentColor" > </path > <path d ="M7 ..." fill ="currentColor" > </path > </svg > 1.1万 </span > </div > </div > </div > </div > </li >
这些信息都在list中存储,我们可以通过对每一项施加get_attribute()或者find_element()方法来获得想要的信息。
我们重点关注以下几个信息:
1、<li data-id="113560092935193" data-rank="1" class="rank-item" scrollshow="true">中的id和date-rank,分别表示视频的id、数据是第几个。
2、<a href="//www.bilibili.com/video/BV1ZBzhYREVs" target="_blank" title="《崩坏:星穹铁道》千星纪游PV:「太阳落下之后」" class="title">《崩坏:星穹铁道》千星纪游PV:「太阳落下之后」</a>中包含视频标题。
3、<span class="data-box up-name">崩坏星穹铁道</span>中包含up主名字。
4、<div class="detail-state"><span class="data-box">较为特殊,里面包含了两个并列的信息,分别是播放量和弹幕量。
get_attribute()获取属性名 Selenium中获得元素属性的方法get_attribute()有以下几种用法:
1、get_attribute('textContent')会获取标签之间的文本内容;
2、get_attribute('innerHTML')会获取标签之间的完整 html;
3、get_attribute('outerHTML')获取当前标签的完整 html;
4、get_attribute('date-id')获取元素属性data-id;
5、get_attribute('目标属性名')获取任何我们想要得到的属性名,比如href、id、class等。
所以,视频id和排序我们可以这样获得:
for item in video_items: video_id = item.get_attribute('data-id' ) rank = item.get_attribute('data-rank' ) print (f"Video ID: {video_id} " ) print (f"Rank: {rank} " ) print ("------" )
我们可以看到有100个视频的id和排序已经出现了:
Video ID: 113560092935193 Rank: 1 ------ Video ID: 113565377763252 Rank: 2 ------ Video ID: 113567978226144 Rank: 3 ------ ...
find_element()和CSS选择器获取文本内容 接下来我们试着提取视频名和up主名,我们可以采用**find_element 方法,在当前每一个item元素的子孙元素中,通过CSS 选择器: By.CSS_SELECTOR**来查找元素找到名为title的class类,并获取其文本内容。注意,一定要在最后加上.text来获取文本内容,否则获得的就是一些引用。
title = item.find_element(By.CSS_SELECTOR, '.title' ).text uploader = item.find_element(By.CSS_SELECTOR, '.up-name' ).text
把这段代码加到for循环中,看到正确输出了视频名和up主名。
for item in video_items: video_id = item.get_attribute('data-id' ) rank = item.get_attribute('data-rank' ) title = item.find_element(By.CSS_SELECTOR, '.title' ).text uploader = item.find_element(By.CSS_SELECTOR, '.up-name' ).text print (f"Video ID: {video_id} " ) print (f"Rank: {rank} " ) print (f"Title: {title} " ) print (f"Uploader: {uploader} " ) print ("------" )
Video ID: 113560092935193 Rank: 1 Title: 《崩坏:星穹铁道》千星纪游PV:「太阳落下之后」 Uploader: 崩坏星穹铁道 ------ Video ID: 113565377763252 Rank: 2 Title: 鏖战百万级蟑螂大军(非虚数),心理阴影面积比太平洋还大 Uploader: 马俐管家 ------ Video ID: 113567978226144 Rank: 3 Title: 你是我灰蒙蒙世界里的小太阳 Uploader: 星有野 ------ ...
当然,代码中为了简单,在提取up主时,只用了'.up-name'这一个条件,也可以采用'.data-box.up-name',来匹配同时拥有 data-box 和 up-name 类的 <span> 元素,效果是一样的。
之后我们爬取播放量和弹幕量,可是这两个参数都在一个<div class="detail-state">中,在下一级,两者分别位于类名都是<span class="data-box">的<span>元素里。如果按照刚刚的提取方法,会出现两个数字无法区分的情况。
所以,我们采用伪类选择器来获取父类<div class="detail-state">中第一个和第二个<span>子元素。
view_count = item.find_element(By.CSS_SELECTOR, '.detail-state .data-box:nth-child(1)' ).text comment_count = item.find_element(By.CSS_SELECTOR, '.detail-state .data-box:nth-child(2)' ).text
代码解释:'.detail-state .data-box:nth-child(1)'是一个 CSS 选择器,用于定位 detail-state 类内部第一个 .data-box 类元素。nth-child(1) 伪类选择器用于选择其父元素的第一个子元素,在这里与 .data-box 结合使用,确保选择的是 .detail-state 下的第一个 .data-box 元素。
注意,这种方法只适用于结构化的,规范的数据。
添加到for循环中,看到有正确的输出。
for item in video_items: video_id = item.get_attribute('data-id' ) rank = item.get_attribute('data-rank' ) title = item.find_element(By.CSS_SELECTOR, '.title' ).text uploader = item.find_element(By.CSS_SELECTOR, '.up-name' ).text view_count = item.find_element(By.CSS_SELECTOR, '.detail-state .data-box:nth-child(1)' ).text comment_count = item.find_element(By.CSS_SELECTOR, '.detail-state .data-box:nth-child(2)' ).text print (f"Video ID: {video_id} " ) print (f"Rank: {rank} " ) print (f"Title: {title} " ) print (f"Uploader: {uploader} " ) print (f"View_count: {view_count} " ) print (f"Comment_count: {comment_count} " ) print ("------" )
Video ID: 113560092935193 Rank: 1 Title: 《崩坏:星穹铁道》千星纪游PV:「太阳落下之后」 Uploader: 崩坏星穹铁道 View_count: 289.1万 Comment_count: 1.1万 ------ Video ID: 113565377763252 Rank: 2 Title: 鏖战百万级蟑螂大军(非虚数),心理阴影面积比太平洋还大 Uploader: 马俐管家 View_count: 265.5万 Comment_count: 4.8万 ------ Video ID: 113567978226144 Rank: 3 Title: 你是我灰蒙蒙世界里的小太阳 Uploader: 星有野 View_count: 165.6万 Comment_count: 2770 ------
3.4、保存数据 现在,我们解决存储的问题,一般爬取的数据要存在exl中,我们以excel的格式会更加方便处理和展示。
一般写入excel文件的步骤如下:
1、导入必要的库 首先,要导入pandas库和openpyxl库。在我的代码中,openpyxl库并没有被使用,但是它是处理exl文件相当重要的库,它帮助用户创建、修改、分析Excel中的数据。
2、准备数据 通常我们会用列表(list)或字典(dict)来存储爬虫爬到的数据。
我们现在用到的是列表,每一行就是list中的一项,列表中每一项都是一个字典。
data = [] video_info = { 'Video ID' : video_id, 'Rank' : rank, 'Title' : title, 'Uploader' : uploader, 'View Count' : view_count, 'Comment Count' : comment_count } data.append(video_info)
3、创建DataFrame DataFrame是pandas中的一个二维数据结构,类似于Excel中的表格。使用pandas.DataFrame ()函数来创建一个DataFrame对象。把我们已经追加好的list转化成DataFrame结构。
Tips:如果数据字典中有明确的键名,那么这些键名将自动成为DataFrame的列名。此时我们的数据已经有列名了,但是我想要一个中文的列名。
4、设置列名(可选) 使用DataFrame.columns属性来设置或重命名列名。
df.columns = ['视频id' , '排序' , '视频标题' , 'up主' , '播放量' , '弹幕量' ]
5、写入Excel文件 使用DataFrame的to_excel(路径/文件名, index)方法将数据写入Excel文件。需要指定文件名和路径,以及是否要写入行索引(默认情况下,pandas会写入一个从0开始的整数索引),行索引就是在最左边再加上新的一列,从0开始依次往后。
output_file = 'bilibili热门视频排行.xlsx' df.to_excel(output_file, index=False )
6、设置Excel文件的样式和格式 上面我们用到的to_excel()方法提供了许多其他参数,允许你设置Excel文件的样式和格式,如引擎(用于写入Excel的库)、sheet_name(工作表名称)、encoding(文本编码)等。此外,还可以使用openpyxl或xlsxwriter等库来进一步自定义Excel文件的样式和格式。
对于大多数基本用例来说,to_excel的默认设置已经足够。
7、验证和保存 最后,输出一句话来代表文件已经写入,并打开它来验证数据是否完整且格式正确。
print (f"Data has been saved to {output_file} " )
3.5、完整代码与小结 最后,我们要关闭webdrive防止占用系统资源。
最终完整代码如下:
from selenium import webdriverfrom selenium.webdriver.common.by import Byimport pandas as pddriver = webdriver.Edge() driver.get("https://www.bilibili.com/v/popular/rank/all" ) video_items = driver.find_elements(By.CSS_SELECTOR,'li.rank-item' ) total_items = len (video_items) print (f"总项数是: {total_items} " )data = [] for item in video_items: video_id = item.get_attribute('data-id' ) rank = item.get_attribute('data-rank' ) title = item.find_element(By.CSS_SELECTOR, '.title' ).text uploader = item.find_element(By.CSS_SELECTOR, '.up-name' ).text view_count = item.find_element(By.CSS_SELECTOR, '.detail-state .data-box:nth-child(1)' ).text comment_count = item.find_element(By.CSS_SELECTOR, '.detail-state .data-box:nth-child(2)' ).text video_info = { 'Video ID' : video_id, 'Rank' : rank, 'Title' : title, 'Uploader' : uploader, 'View Count' : view_count, 'Comment Count' : comment_count } data.append(video_info) df = pd.DataFrame(data) df.columns = ['视频id' , '排序' , '视频标题' , 'up主' , '播放量' , '弹幕量' ] output_file = 'bilibili热门视频排行.xlsx' df.to_excel(output_file, index=False ) print (f"Data has been saved to {output_file} " )drive.quit()
在这个案例中,我们熟悉了python结合selenium爬取数据的一般流程,熟悉了在页面上定位目标元素,熟悉了在<li>元素中提取数据的方法,熟悉了list类型保存为exl的操作,难点在于get_attribute()和find_element()的使用。
接下来放两个关于难点函数的详解链接。
get_attribute():
selenium中get_attribute的几种用法_selenium get attribute-CSDN博客 ;
RPA手把手:selenium 中 get_attribute 的几种用法 - 知乎 。
find_element():
web自动化系列-selenium find_elements定位方法详解(八) - 知乎 。
因为selenium是模拟人操作浏览器的过程,所以要解决一些实际要面对的问题,比如:”怎么判断页面加载完成?遇到弹窗怎么办?如何翻页?”等等。之后我们先逐个解决这些问题,再通过案例2来实战和强化。
4、如何等待页面加载完成? Selenium最常见的等待方法是隐式等待和显式等待,当然也有直接采用time.sleep()的傻瓜式方法。
4.1、隐式等待 隐式等待是全局设置的,其核心思想是:在进行点击、输入等操作时,要先能检索到目标元素,能检索到就说明已经加载完成,再进行操作。
通过调用WebDriver对象的implicitly_wait()方法,传入一个等待时间(单位为秒),开启隐式等待。
from selenium import webdriverdriver = webdriver.Chrome() driver.implicitly_wait(10 ) driver.get("http://www.baidu.com" ) element = driver.find_element_by_id("someElementId" )
隐式等待时,Selenium通过轮询 的方式来检查元素是否出现,在设定的等待时间内,WebDriver会不断刷新页面或检查DOM树,直到指定的元素(通常间隔0.5秒,但这个间隔是Selenium的内部实现细节,具体因版本而异)。如果在指定时间内没有出现,会抛出一个NoSuchElementException异常。
4.2、显式等待 显式等待是针对某一条命令单独设置的,通常针对某一条重要命令,或者该命令的数据量较大时使用,用来等待某个元素可见或者可点击。
通过结合使用WebDriverWait类与until方法来开启显式等待,系统在设定的时间内判断元素是否出现,主要依靠条件(condition)和定时器(timer)。 当调用WebDriverWait的until方法时,系统会启动一个定时器,该定时器在指定的等待时间内持续计时。跳出这个计时器需要传入一个条件(condition),这个条件通常是一个函数或lambda表达式,它表示等待的目标。
from selenium import webdriverfrom selenium.webdriver.common.by import Byfrom selenium.webdriver.support.ui import WebDriverWaitfrom selenium.webdriver.support import expected_conditions as ECdriver = webdriver.Chrome() driver.get("http://www.baidu.com" ) try : element = WebDriverWait(driver, 10 ).until( EC.visibility_of_element_located((By.ID, "someElementId" )) ) element.click() finally : driver.quit()
Selenium为显式等待提供了预定义的条件,如EC.visibility_of_element_located、EC.presence_of_element_located等。如果定时器结束,函数仍未返回满足条件的结果,则WebDriverWait会抛出一个TimeoutException异常,表示等待超时。
4.3显式等待和隐式等待的对比以及time.sleep() 显式等待 :针对特定的查找操作或条件进行等待,直到条件满足或超时。
隐式等待 :在整个WebDriver实例的生命周期内,对所有元素的查找操作进行全局等待。
简单来说,隐式等待全局有效,只用设定一次,所以其简单易用,代码冗余度低;显式等待局部有效,需要设定多次,但精确度高、灵活性好、排查错误更清晰。
显式等待在等待条件不满足时会抛出明确的TimeoutException异常,使得测试人员能够清楚地定位失败的原因;而隐式等待只抛出NoSuchElementException异常,错误处理不够明确。
两者不建议混合使用,因为当两者同时使用时,显式等待的查找操作也会触发隐式等待,这两个等待机制可能会相互干扰,导致等待时间延长或缩短,出现难以预测的行为。
对于网页复杂、精度要求高的爬虫,建议采用显式等待。
同时,也可以采用time.sleep()来进行测试,有时适度的使用虽然减慢了效率但可以大大减少代码的复杂性。
5、如何处理页面弹窗? 页面的弹窗多种多样,大体上分为两类:
1、基于JS触发的浏览器自带弹窗,比如Alert、Confirm、Prompt;
2、基于html的自定义弹窗,通常由html元素实现。
5.1、处理基于JS触发的弹窗 Alert弹窗是显示一个提示框,只有【确定】一个选项。
<!DOCTYPE html > <html > <head > <meta charset ="utf-8" > <script > alert ("这是弹出框提示文本" ) </script > <title > </title > </head > <body > <p > alert是阻塞的函数</p > <p > 这句话只有在确认弹出框的提示文本后才会显示</p > </body > </html >
Confirm弹窗含有指定消息,有【确认】和【取消】两个按钮,点击后分别返回true和false。
<!DOCTYPE html > <html > <head > <meta charset ="utf-8" > <script > confirm ("这样写可以直接显示,不接收返回值。" ) var x; var r=confirm ("请按下按钮!" ); if (r==true ){ x="你按下的是\"确定\"按钮。" ; } else { x="你按下的是\"取消\"按钮。" ; } document .write (x) </script > <title > </title > </head > <body > </body > </html >
Prompt弹窗是显示提示用户进行输入的对话框,返回用户输入的字符串。
<!DOCTYPE html > <html > <head > <meta charset ="utf-8" > <script > prompt ("开心吗?" ); var x; var name=prompt ("请输入你的名字" ,"Keafmd" ); if (name!=null && name!="" ){ x="你好! " + name + "。" ; document .write (x) } </script > <title > </title > </head > <body > </body > </html >
处理以上三种基于JS的弹窗方法类似,都需要先用driver.switch_to.alert获取弹窗对象,最后用accept()方法接受。
Alert弹窗
Confirm弹窗
Prompt弹窗
使用driver.switch_to.alert获取弹窗对象。
使用driver.switch_to.alert获取弹窗对象。
使用driver.switch_to.alert获取弹窗对象。
使用accept()方法接受弹窗。
使用accept()方法接受弹窗,或使用dismiss()方法取消弹窗。
使用send_keys()方法向输入框中输入文本。
使用accept()方法接受弹窗。
以下是处理三种弹窗的示例代码。
from selenium import webdriverfrom selenium.webdriver.common.alert import Alertfrom selenium.webdriver.common.by import Byimport timetry : driver.get('https://example.com/alert-page' ) alert_button = driver.find_element(By.ID, 'alert-button-id' ) alert_button.click() alert = driver.switch_to.alert alert.accept() time.sleep(2 ) confirm_button = driver.find_element(By.ID, 'confirm-button-id' ) confirm_button.click() confirm_alert = driver.switch_to.alert confirm_alert.accept() time.sleep(2 ) prompt_button = driver.find_element(By.ID, 'prompt-button-id' ) prompt_button.click() prompt_alert = driver.switch_to.alert prompt_alert.send_keys('Your input text' ) prompt_alert.accept() time.sleep(2 ) finally : driver.quit()
5.2、处理基于html的弹窗 处理基于html的弹窗时,和对页面交互的逻辑相同,因为都是在html的层级来用selenium操作。大致流程为:1、定位弹窗元素;2、交互;3、关闭。
如何定位弹窗元素在此后进行讲解,这里只放上思路和示例代码。
from selenium import webdriverfrom selenium.webdriver.common.by import Byfrom selenium.webdriver.support.ui import WebDriverWaitfrom selenium.webdriver.support import expected_conditions as ECdriver.get('http://example.com' ) modal = WebDriverWait(driver, 10 ).until(EC.visibility_of_element_located((By.ID, 'modal' ))) close_button = driver.find_element(By.CSS_SELECTOR, '.close' ) close_button.click() driver.quit()
本文先不深入探讨处理动态js加载的问题,有了以上两个问题的储备,我们之后通过实战来深入学习。
6、案例二:爬取千里马招标数据 6.1、任务需求 编写python爬虫,爬取千里马网站的招标信息,在【招标信息】中用【标题】搜索【档案+监理】,爬取2013-2023年的【详细数据】,并按年份保存为excel文件。
具体流程如下:
1、配置Edge WebDrive; 2、访问并登录千里马网页;3、搜索和筛选到目标数据页面;4、循环遍历每个年份并爬取数据;5、写入excel文件并保存;6、关闭进程。
6.2、完整代码 该项目不做具体步骤的讲解,只附上完整代码。
import mathimport timeimport pandas as pdfrom selenium import webdriverfrom selenium.webdriver.common.by import Byfrom selenium.webdriver.support.ui import WebDriverWaitfrom selenium.webdriver.support import expected_conditions as ECfrom selenium.common.exceptions import NoSuchElementException, TimeoutException, StaleElementReferenceExceptiondriver = webdriver.Edge() driver.get('https://qianlima.com/' ) driver.implicitly_wait(15 ) img_element = WebDriverWait(driver, 10 ).until( EC.element_to_be_clickable((By.XPATH, '//img[contains(@src, "iVBORw0KGgoAAAANSUhEUgAAAB4AAAAeCAMAAAAM7l6Q")]' )) ) img_element.click() close_button = WebDriverWait(driver, 10 ).until( EC.element_to_be_clickable((By.ID, "close-1" )) ) close_button.click() login_button = WebDriverWait(driver, 10 ).until( EC.element_to_be_clickable((By.CSS_SELECTOR, "[data-extendinfo='登录']" )) ) login_button.click() driver.switch_to.window(driver.window_handles[1 ]) username_input = WebDriverWait(driver, 10 ).until( EC.presence_of_element_located((By.NAME, "username" )) ) username_input.send_keys('xxxxxx' ) password_input = WebDriverWait(driver, 10 ).until( EC.presence_of_element_located((By.NAME, "password" )) ) password_input.send_keys('xxxxxx' ) login_button = WebDriverWait(driver, 10 ).until( EC.element_to_be_clickable((By.XPATH, "//button[span[contains(text(), '登录')]]" )) ) login_button.click() dropdown_trigger = WebDriverWait(driver, 10 ).until( EC.element_to_be_clickable((By.ID, "intention-search" )) ) dropdown_trigger.click() WebDriverWait(driver, 10 ).until( EC.presence_of_element_located((By.CSS_SELECTOR, "[data-val='2']" )) ) option_with_data_val_2 = driver.find_element(By.CSS_SELECTOR, "[data-val='2']" ) option_with_data_val_2.click() search_input = WebDriverWait(driver, 10 ).until( EC.visibility_of_element_located((By.ID, "toSearchValue" )) ) search_input.send_keys("档案+监理" ) search_button = driver.find_element(By.ID, "toSearchBtn" ) search_button.click() driver.implicitly_wait(10 ) driver.switch_to.window(driver.window_handles[2 ]) while True : try : bidding_info_div = WebDriverWait(driver, 10 ).until(EC.element_to_be_clickable((By.XPATH, "//div[@id='searchTab']//div[p='中标信息']" ))) bidding_info_div.click() break except StaleElementReferenceException: print ("retrying..." ) time.sleep(1 ) detail_element = WebDriverWait(driver, 10 ).until( EC.element_to_be_clickable((By.XPATH, '//div[@class="summary-item fl" and text()="明细"]' ))) detail_element.click() start_year = 2016 end_year = 2023 for year in range (start_year, end_year + 1 ): print (f"正在爬取{year} 年的数据..." ) try : time.sleep(1 ) year_selector = f'div.freeYearItem[data-name="{year} 年"]' list_item = WebDriverWait(driver, 10 ).until( EC.element_to_be_clickable((By.CSS_SELECTOR, 'li.listItem.fl.listItem40' ))) list_item.click() time.sleep(1 ) year_click = WebDriverWait(driver, 10 ).until( EC.element_to_be_clickable((By.CSS_SELECTOR, year_selector))) year_click.click() time.sleep(1 ) data_list = [] columns = [ 'Title标题' , 'URL连接' , 'Date日期' , 'Location地点' , 'Type类型' , 'winning_unit中标单位' , 'winning_price中标价格' , 'tender_unit招标单位' , 'budget招标预算' , 'agency_unit代理单位' , 'description正文预览' ] total_num_element = driver.find_element(By.ID, 'totalNum' ) total_num_value = total_num_element.text print (total_num_value) recycle_num = math.ceil(int (total_num_value) / 20 ) print (recycle_num) for _ in range (recycle_num): WebDriverWait(driver, 10 ).until(EC.presence_of_element_located((By.CLASS_NAME, 'container-con' ))) next_button = WebDriverWait(driver, 10 ).until(EC.element_to_be_clickable((By.CSS_SELECTOR, '.next.fr' ))) li_elements = driver.find_elements(By.XPATH, '//ul[@class="container-con"]/li' ) for li in li_elements: title = li.find_element(By.CLASS_NAME, 'con-title' ).text url = li.find_element(By.CLASS_NAME, 'con-title' ).get_attribute('href' ) date = li.find_element(By.CLASS_NAME, 'con-time' ).text location = li.find_element(By.XPATH, './/div[@class="con-bottom clear-both"]/p[@class="fl"]/a[not(contains(@class, "con-type"))]' ).text type_ = li.find_element(By.XPATH, './/div[@class="con-bottom clear-both"]/p[@class="fl"]/a[contains(@class, "con-type")]' ).text summary_blocks = li.find_elements(By.CSS_SELECTOR, 'div.summary-block' ) tender_unit = '' for block in summary_blocks: if '招标单位:' in block.text: tender_unit = block.text.split(':' )[1 ] break agency_unit = '' for block in summary_blocks: if '代理单位:' in block.text: agency_unit = block.text.split(':' )[1 ] break winning_unit = '' for block in summary_blocks: if '中标单位:' in block.text: winning_unit = block.text.split(':' )[1 ] break winning_price = '' for block in summary_blocks: if '中标价格:' in block.text: winning_price = block.text.split(':' )[1 ] break budget = '' for block in summary_blocks: if '招标预算:' in block.text: budget = block.text.split(':' )[1 ] break description = '' for block in summary_blocks: if '正文预览:' in block.text: description = block.text.split(':' )[1 ] break data_list.append([title, url, date, location, type_, winning_unit, winning_price, tender_unit, budget, agency_unit, description]) next_button.click() time.sleep(0.6 ) file_name = f'千里马数据爬取_{year} .xlsx' df = pd.DataFrame(data_list, columns=columns) df.to_excel(file_name, index=False ) print (f'已保存 {file_name} ' ) except (NoSuchElementException, TimeoutException) as e: print (f"爬取{year} 年数据失败: {e} " ) continue driver.quit()