
人工智能入门04-华为昇腾实习笔记-初识ModelArts
5.22-5.23学习:
- 观看 AI基础理论-人工智能理论-《开放环境下的自适应视觉感知》
- 阅读并理解文档《MindSpore ModelArts昇腾训练最佳实践》
- -修改文档并实践(见下一篇笔记)
- 学习“文档首页> AI开发平台ModelArts> 产品介绍”
- -图解ModelArts
- -什么是ModelArts
- -功能介绍
- -基础知识(重点)
- -ModelArts支持的框架
- -与其他服务的关系
- -如何访问ModelArts
- ModelArts产品术语
- AI Gallery
本教程博主开始熟悉ModelArts,包括基本知识和流程,属于理论学习。
图解ModelArts
此时再看ModelArts已经比第一眼熟悉了很多,但是这个图并没有完全理解和体会,等做完实验能在平台上跑起来模型了之后再回来看。

对于workflow流水线工具,图片带给我的理解非常浅显。

什么是ModelArts
ModelArts一站式AI开发平台,提供数据预处理、分布式训练、自动化模型生成及端-边-云模型按需部署能力,帮助用户快速创建和部署模型,管理全周期AI工作流。
“一站式”是指AI开发的各个环节,数据处理、算法开发、模型训练、模型部署都可以在ModelArts上完成。
ModelArts最明显的两个特点
ModelArts的兼容性好:ModelArts底层支持各种异构计算资源,支持Tensorflow、PyTorch、MindSpore等主流开源的AI开发框架,也支持开发者使用自研的算法框架。
ModelArts的易用性好:面向业务开发者,不需关注模型或编码,可使用自动学习流程快速构建AI应用;面向AI初学者,不需关注模型开发,使用预置算法构建AI应用;面向AI工程师,提供多种开发环境,多种操作流程和模式,方便开发者编码扩展,快速构建模型及应用。
ModelArts产品的三种形态
ModelArts Standard:面向AI开发全流程,构建端到端的模型生产工具链,实现高效、易用的AI开发、训练和推理。提供数据管理、模型开发与训练、推理部署、开发工具链等功能,实现AI全流程生命周期管理。
ModelArts Lite:包含弹性裸金属和弹性集群2种模式,适用于已经自建AI开发平台,仅有算力需求的用户,提供高性价比的AI算力,并预装主流AI开发套件以及加速插件。
1、弹性裸金属DevServer:面向云主机资源型用户,基于裸金属服务器进行封装,可以通过弹性公网IP进行访问操作。
2、弹性集群Cluster:面向k8s资源型用户,提供k8s原生接口,用户可以直接操作资源池中的节点和k8s集群。
ModelArts Edge:支持边云协同推理,高效利用边缘资源,提供边缘应用安全保障。主要应用于服务器、边缘盒子、智能摄像头、开发板等在线或离线边缘AI推理场景。
ModelArts产品架构图:
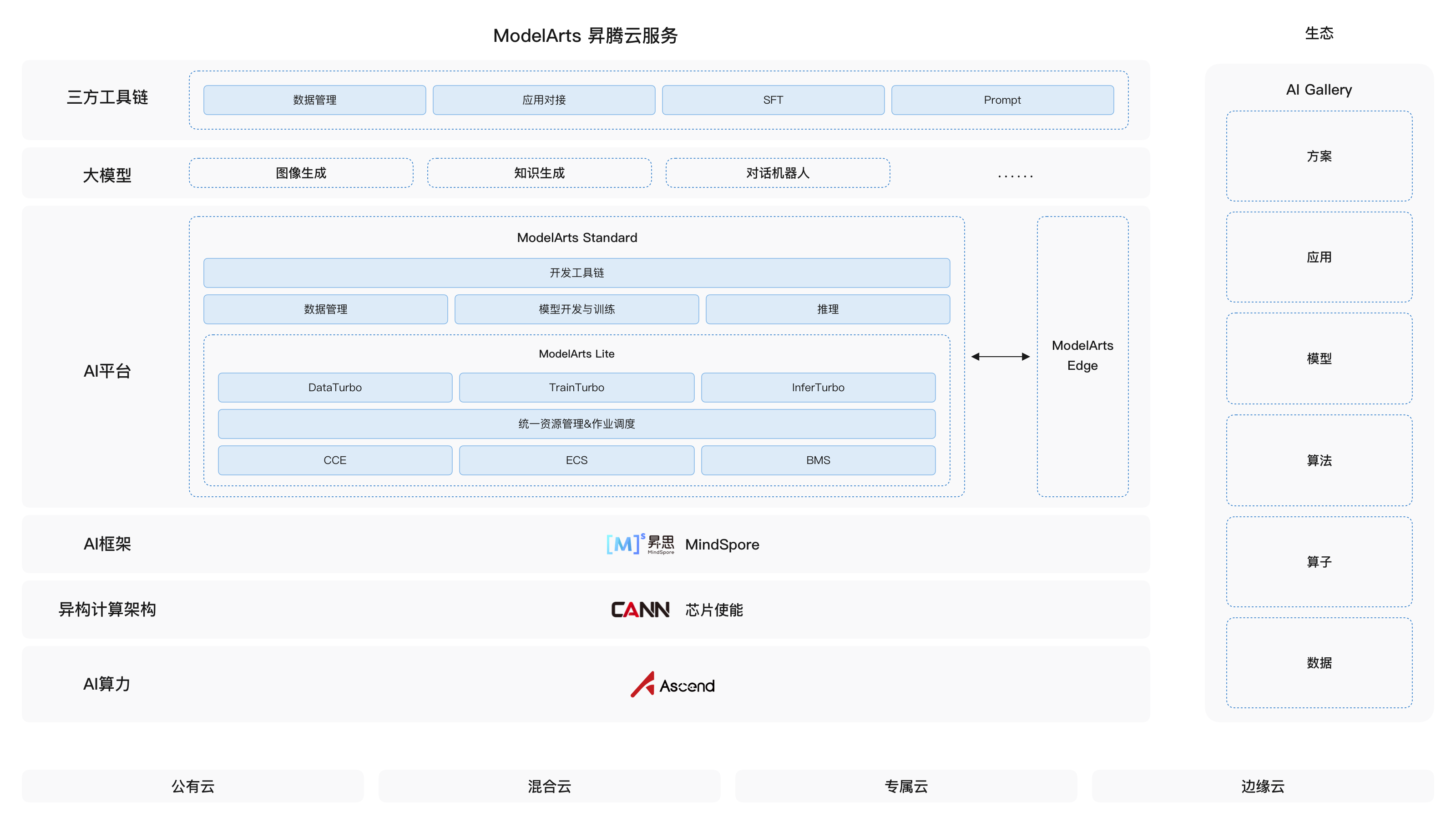
功能介绍
ModelArts特色功能如下所示:
1、数据治理:支持数据筛选、标注等数据处理,提供数据集版本管理,特别是深度学习的大数据集,让训练结果可重现。
2、极快致简模型训练:自研的MoXing深度学习框架,更高效更易用,有效提升训练速度。
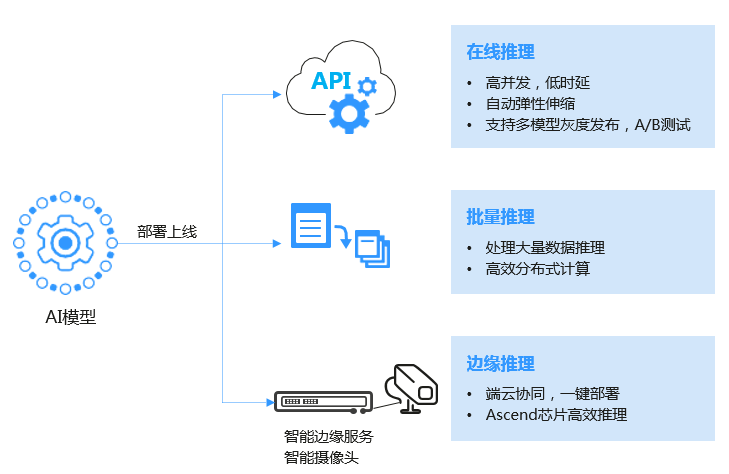
3、多场景部署:支持模型部署到多种生产环境,可部署为云端在线推理和批量推理,也可以直接部署到端和边。
4、自动学习:支持多种自动学习能力,通过“自动学习”训练模型,用户不需编写代码即可完成自动建模、一键部署。
5、AI Gallery:预置常用算法和常用数据集,支持把模型放在企业内部共享或者公开共享。
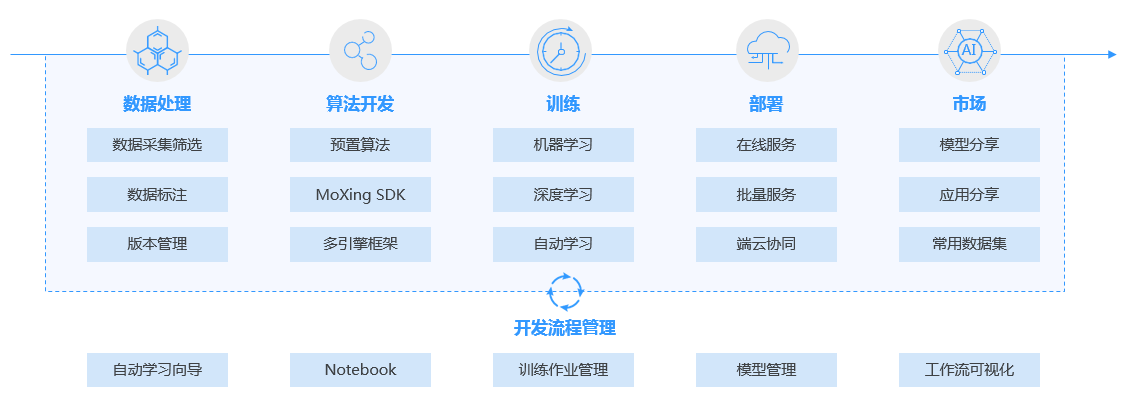
基础知识
AI开发基本流程介绍
首先,AI的本质是什么?
AI是通过机器来模拟人类认识的一种技术。AI的本质是根据给定的输入做出判断或预测。
AI开发的基本流程可以归纳为5个步骤:确定目的、准备数据、训练模型、评估模型、部署模型。

AI开发基本概念
机器学习常见的分类有3种:
1、监督学习:利用一组已知类别的样本调整分类器的参数(已加标签),使其达到所要求性能的过程。常见的监督学习有回归和分类。
2、非监督学习:在未加标签的数据中,试图找到隐藏的结构。常见的有聚类。
3、强化学习:智能系统从环境到行为映射的学习(感知环境、做出行为),以使奖励信号(强化信号)函数值最大。
回归:回归反映的是数据属性值在时间上的特征,产生一个将数据项映射到一个实值预测变量的函数,发现变量或属性间的依赖关系,其主要研究问题包括数据序列的趋势特征、数据序列的预测以及数据间的关系等。
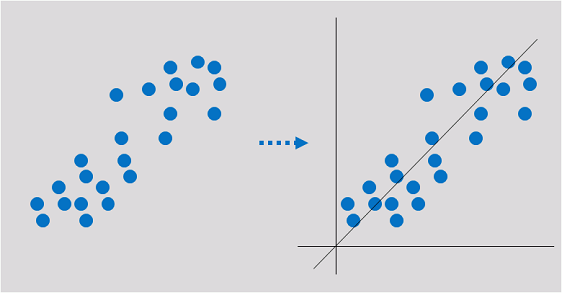
分类:分类是找出一组数据对象的共同特点并按照分类模式将其划分为不同的类,其目的是通过分类模型,将数据项映射到某个给定的类别。
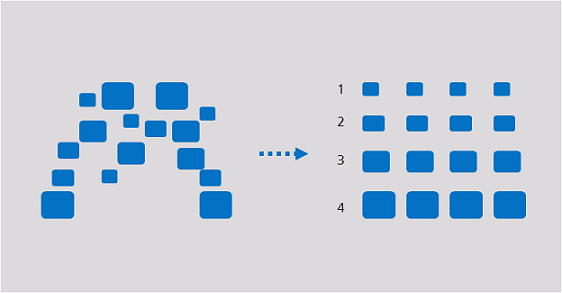
聚类:聚类是把一组数据按照相似性和差异性分为几个类别,其目的是使得属于同一类别的数据间的相似性尽可能大,不同类别中的数据间的相似性尽可能小。
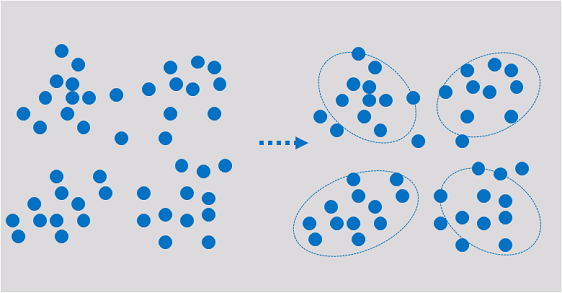
ModelArts中常用概念
自动学习
自动学习功能可以根据标注数据自动设计模型、自动调参、自动训练、自动压缩和部署模型,不需要代码编写和模型开发经验。只需三步,标注数据、自动训练、部署模型,即可完成模型构建。
端-边-云
端-边-云分别指端侧设备、智能边缘设备、公有云。
推理
指按某种策略由已知判断推出新判断的思维过程。人工智能领域下,由机器模拟人类智能,使用构建的神经网络完成推理过程。
在线推理
在线推理是对每一个推理请求同步给出推理结果的在线服务(Web Service)。
资源池
ModelArts提供的大规模计算集群,可应用于模型开发、训练和部署。支持公共资源池和专属资源池两种。ModelArts默认提供公共资源池,按需计费。专属资源池需单独创建,专属使用,不与其他用户冲突。
AI Gallery
AI_Gallery_AI模型案例_华为云 (huaweicloud.com),AI市场预置了常用模型和算法,可以直接获取使用。您也可以将自己开发的模型、算法或数据集分享至市场,公开共享。
MoXing
MoXing是ModelArts自研的组件,是一种轻型的分布式框架,构建于TensorFlow、PyTorch、MXNet、MindSpore等深度学习引擎之上,使得这些计算引擎分布式性能更高,同时易用性更好。
MoXing包含很多组件,其中MoXing Framework模块是一个基础公共组件,可用于访问OBS服务,和具体的AI引擎解耦,在ModelArts支持的所有AI引擎(TensorFlow、MXNet、PyTorch、MindSpore等)下均可以使用。MoXing Framework模块提供了OBS中常见的数据文件操作,如读写、列举、创建文件夹、查询、移动、复制、删除等。
在ModelArts Notebook中使用MoXing接口时,可直接调用接口,无需下载或安装SDK,使用限制比ModelArts SDK和OBS SDK少,非常便捷。
数据管理
AI开发过程中经常需要处理海量数据,数据准备与标注会耗费整体开发时间一半以上。
ModelArts数据管理提供了一套高效便捷的管理和标注数据框架。支持图片、文本、语音、视频等多种数据类型,涵盖图像分类、目标检测、音频分割、文本分类等多个标注场景,可适用于计算机视觉、自然语言处理、音视频分析等多种AI项目;同时提供了数据筛选、数据分析、数据处理、智能标注、团队标注以及版本管理等功能,AI开发者可基于该框架实现数据标注全流程处理。
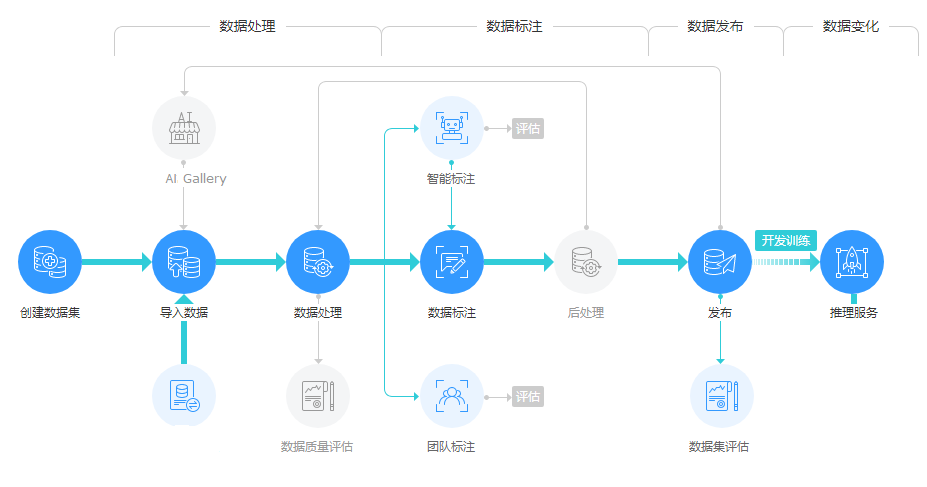
数据管理平台提供了聚类分析、数据特征分析、数据清洗、数据校验、数据增强、数据选择等分析处理能力。开发者可以在线完成图像分类、目标检测、音频分割、文本三元组、视频分类等各种标注场景任务。同时,也可以使用ModelArts智能标注方案,通过预置算法或自定义算法代替人工完成数据标注,提升标注效率。
针对大规模协同标注场景,数据管理平台还提供了团队标注功能,支持标注团队管理、人员管理、角色管理等,实现从项目的创建、数据分配、进度把控、标注、审核、验收全流程。
开发环境
远程开发 - 支持本地IDE远程访问Notebook
Notebook提供了远程开发功能,通过开启SSH连接,用户本地IDE可以远程连接到ModelArts的Notebook开发环境中,调试和运行代码。
对于使用本地IDE的开发者,由于本地资源限制,运行和调试环境大多使用团队公共搭建的资源服务器,并且是多人共用,而ModelArts的Notebook的优势是即开即用,它预装了不同的AI引擎,并且提供了非常多的可选规格,用户可以独占一个容器环境,不受其他人的干扰。
ModelArts的Notebook虽然是云应用,但可以视作是本地PC的延伸,均可视作本地开发环境,其读取数据、训练、保存文件等操作与常规的本地训练一致。本地IDE当前支持VS Code、PyCharm、SSH工具。另有插件PyCharm Toolkit和VS Code Toolkit,方便将云上资源作为本地的扩展。
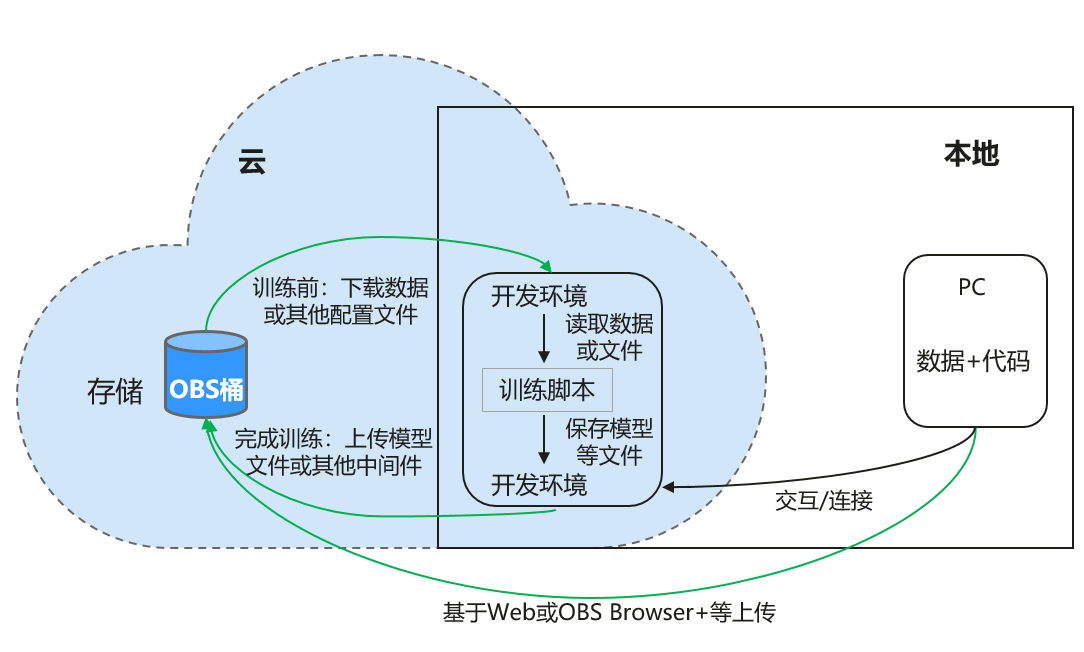
开发环境保存 - 支持一键镜像保存
ModelArts的新版Notebook提供了镜像保存功能。支持一键将运行中的Notebook实例保存为镜像,将准备好的环境保存下来,可以作为自定义镜像,方便后续使用或分享。
保存镜像时,安装的依赖包(pip包)不会丢失,VS Code远程开发场景下,在Server端安装的插件不丢失。
预置镜像 - 即开即用,优化配置,支持主流AI引擎
ModelArts开发环境给用户提供了一组预置镜像,主要包括PyTorch、Tensorflow、MindSpore系列。用户可以直接使用预置镜像启动Notebook实例,在实例中开发完成后,直接提交到ModelArts训练作业进行训练,而不需要做适配。
ModelArts开发环境提供的预置镜像主要包含:
1、常用预置包,基于标准的Conda环境,预置了常用的AI引擎(PyTorch、MindSpore)、常用的数据分析软件包(Pandas、Numpy等)、常用的工具软件(cuda、cudnn等),满足AI开发常用需求。
2、预置Conda环境:每个预置镜像都会创建一个相对应的Conda环境和一个基础Conda环境python(不包含任何AI引擎),用户可以根据是否使用AI引擎参与功能调试,并选择不同的Conda环境。
3、Notebook:是一款Web应用,能够使用户在界面编写代码,并且将代码、数学方程和可视化内容组合到一个文档中,提供了远程开发功能,通过开启SSH连接,用户本地IDE可以远程连接到ModelArts的Notebook开发环境中,调试和运行代码。
4、JupyterLab插件:插件包括规格切换,分享案例到AI Gallery进行交流,停止实例等。
5、支持SSH远程连接功能,通过SSH连接启动实例,在本地调试就可以操作实例,方便调试。
提供在线的交互式开发调试工具JupyterLab
JupyterLab是一个交互式的开发环境,是Jupyter Notebook的下一代产品,可以使用它编写Notebook、操作终端、编辑MarkDown文本、打开交互模式、查看csv文件及图片等功能。
ModelArts集成了基于开源的JupyterLab,可提供在线交互式开发调试。在ModelArts控制台可以直接使用Notebook编写和调测模型训练代码,然后基于该代码进行模型的训练。
模型训练
模型训练的参数直接影响模型的精度以及模型收敛时间,参数的选择极大依赖于开发者的经验,参数选择不当会导致模型精度无法达到预期结果,或者模型训练时间大大增加。ModelArts提供了基于机器学习等算法自动超参调优的策略,如learning rate、batch size等自动的调参策略;预置和调优常用模型。
当前大多数开发者开发端侧模型时,资源规格限制极为严格。以端侧智能摄像头为例,通常端侧算力在1TFLOPS,内存在2GB规格左右,ROM空间在2GB左右,需要将端侧模型大小控制在百KB级别,推理时延控制在百毫秒级别。这就需要借助模型精度无损或微损下的压缩技术,如通过剪枝、量化、知识蒸馏等技术,实现模型的自动压缩及调优,以保证模型的精度损失极小。
当训练数据量很大时,深度学习模型的训练将会非常耗时。深度学习训练加速一直是学术界和工业界所关注的重要问题。
分布式训练加速需要从软硬件两方面协同来考虑,是一个系统工程。需要从硬件角度考虑分布式训练架构,如系统的整体计算规格、网络带宽、高速缓存、功耗、散热等因素;需要在软件设计结合高性能硬件的特性,通过训练调优算法(混合并行,梯度压缩、卷积加速等),实现分布式训练系统软硬件端到端的高效协同优化,实现多机多卡分布式环境下加速训练。
衡量分布式深度学习的加速性能时,主要有2个重要指标:1、吞吐量:单位时间内处理的数据量;2、收敛时间:达到一定的收敛精度所需的时间。
吞吐量一般取决于服务器硬件、数据读取和缓存、数据预处理、模型计算、通信拓扑等方面的优化。收敛时间需要在优化吞吐量的同时,对调参方面也做调优,调参不到位会导致吞吐量难以优化,当batch size超参不足够大时,模型训练的并行度就会相对较差,吞吐量难以通过增加计算节点个数而提升。
tips:我们在神经网络训练过程中,往往需要将训练数据划分为多个 batch 批次;而具体每一个 batch 有多少个样本,是 batch size 指定的。
模型部署
通常AI模型部署和规模化落地非常复杂。例如,智慧交通项目中,在获得训练好的模型后,需要部署到云、边、端多种场景。如果在端侧部署,需要一次性部署到不同规格、不同厂商的摄像机上,这是一项非常耗时、费力的巨大工程。ModelArts支持将训练好的模型一键部署到端、边、云的各种设备上和各种场景上,并且还为个人开发者、企业和设备生产厂商提供了一整套安全可靠的一站式部署方式。
自动学习
当前仅少数工程师掌握AI的开发和调优能力,大多数算法工程师仅掌握算法原型开发能力,缺少相关的原型落地到产品的能力。
ModelArts通过机器学习的方式帮助不具备开发能力的用户实现算法开发,基于迁移学习、自动神经网络架构搜索实现模型的自动生成,通过算法实现模型的参数自动选择和自动调优,让零基础的开发者可快速完成模型的训练和部署。根据开发者提供的标注数据及选择的场景,无需任何代码开发,可以自动生成满足用户精度要求的模型。可支持图片分类、物体检测、预测分析、声音分类场景。
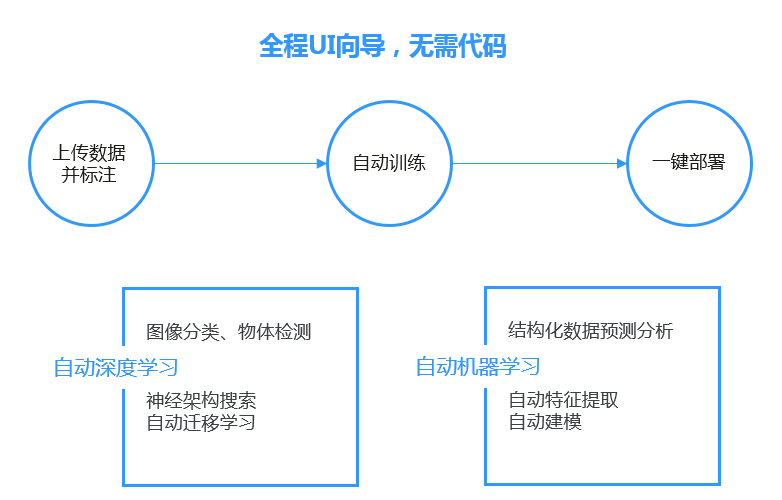
ModelArts的自动学习还开放模型参数,实现模板化开发。对很多资深的开发者说,希望有一款工具可以自动生成模型,在一个半成品的基础上调优,重新训练模型,提高开发效率。
ModelArts支持的框架
ModelArts支持的AI框架_AI开发平台ModelArts (huaweicloud.com)开发需要请参阅最新的说明。
ModelArts与其他服务的关系
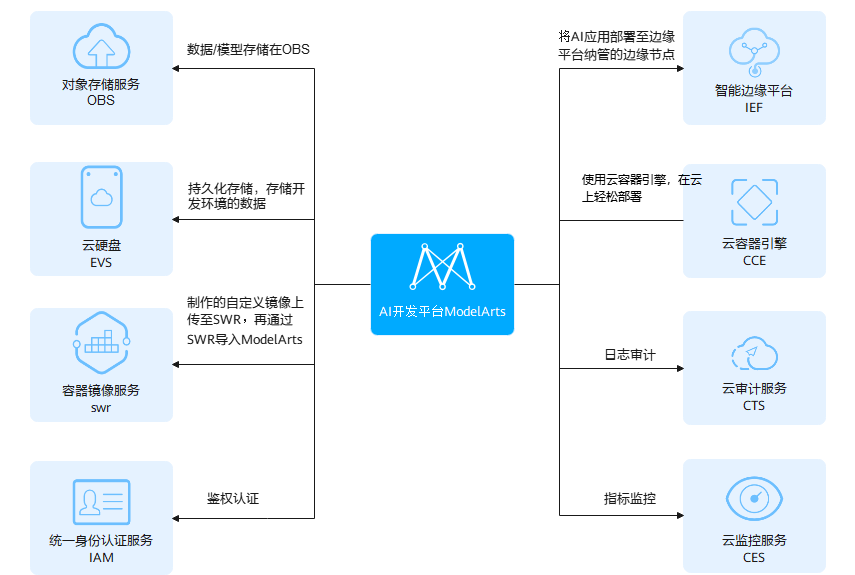
1、与统一身份认证服务的关系:ModelArts使用统一身份认证服务(Identity and Access Management,简称IAM)实现认证功能。
2、与云硬盘的关系:ModelArts使用云硬盘服务(Elastic Volume Service,简称EVS)存储创建的Notebook实例。
3、与云容器引擎的关系:ModelArts使用云容器引擎(Cloud Container Engine,简称CCE)部署模型为在线服务,支持服务的高并发和弹性伸缩需求。
4、与容器镜像服务的关系:当使用ModelArts不支持的AI框架构建模型时,可通过构建的自定义镜像导入ModelArts进行训练或推理。通过容器镜像服务(Software Repository for Container,简称SWR)制作并上传自定义镜像,然后再通过容器镜像服务导入ModelArts。
5、与智能边缘平台的关系:ModelArts可将模型部署至智能边缘平台(Intelligent EdgeFabric,简称IEF)纳管的边缘节点。
6、与云监控的关系:ModelArts使用云监控服务(Cloud Eye Service, 简称CES)监控在线服务和对应模型负载,执行自动实时监控、告警和通知操作。
7、与云审计的关系:ModelArts使用云审计服务(Cloud Trace Service,简称CTS)记录ModelArts相关的操作事件,便于日后的查询、审计和回溯。
8、与对象存储服务的关系:ModelArts使用对象存储服务(Object Storage Service,简称OBS)存储数据和模型,实现安全、高可靠和低成本的存储需求。ModelArts各环节与OBS的关系如下所示。
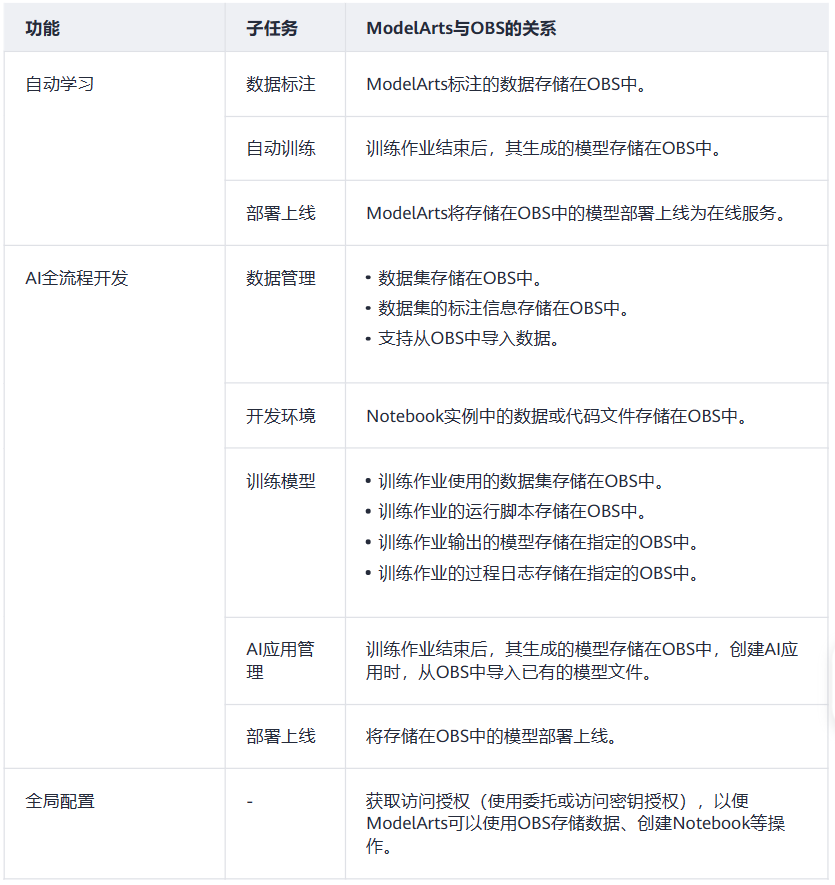
tips:ModelArts创建的Notebook实例存储在EVS中,但notebook实例中的数据和代码存储在OBS中。
如何访问ModelArts
ModelArts提供四种访问方式,分别是:控制台方式、SDK软件开发工具包方式、API程序接口方式、云原生方式。前期简易使用控制台方式。
ModelArts SDK:文档导读_AI开发平台ModelArts (huaweicloud.com)。
ModelArts API:API概览_AI开发平台ModelArts (huaweicloud.com)。
ModelArts 云原生:弹性集群k8s Cluster_AI开发平台ModelArts (huaweicloud.com)。
ModelArts产品术语
这里把原网页引进来,如果需要查看某个术语的意思,直接搜索即可。
AI Gallery
AI Gallery是一个非常优秀的学习平台,其中的教学视频和案例比昇腾社区的要好,对我会有大帮助AI_Gallery_AI模型案例_华为云 (huaweicloud.com)。










