
人工智能入门01-华为昇腾实习笔记-自动求导、张量、计算图、会话、tensorflow
今天正式开始了在华为-洛阳昇腾人工智能实验室的实习,需要快速补习。前期学习内容:学习昇腾社区AI理论基础课程在线课程-昇腾社区 (hiascend.com),熟悉各种名词定义、框架模型,做到初步理解,能在平台跑起来小型AI程序。
5.14-5.15学习:
- 观看 AI基础理论-AI基础模型介绍-《从0到1编写深度学习框架》
- -自动求导原理
- -张量 Tensor
- -算子 Operator
- -计算图 Graph
- -会话 Session
- -简易理解tensorflow运行架构
- -实现一个基于tensorflow的简易深度学习框架
- 观看 AI基础理论-人工智能理论-《人工智能的能与不能》
- 听翁老师讲课《洛阳昇腾人工智能实验室交流-高校科研机构》
以下所有代码都在jupyter notebook中运行,下载链接:https://pan.baidu.com/s/1oWu5I6y3bsU9LRu5aej-Nw?pwd=17ge
提取码:17ge。
自动求导
观看课程《跟李沐学AI》07 自动求导【动手学深度学习v2】07 自动求导【动手学深度学习v2】_哔哩哔哩_bilibili。

[!NOTE]
5.15 对于自动求导怎么应用在深度学习中还没有清晰的认识。
张量 Tensor
参考网页张量简介 | TensorFlow Core (google.cn)。
张量是一个可以运行在GPU上的多维数组。所有张量都是不可变的,张量无法更新,只能创建张量或者销毁张量。
标量就是0秩张量,标量只有1个值,根据以下代码创建一个标量。
import tensorflow as tf |
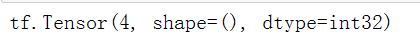
向量是1秩张量,向量是一个值列表,拥有1个轴,根据以下代码创建一个向量。
# Let's make this a float tensor. |
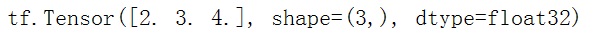
矩阵是2秩张量,拥有2个轴,根据以下代码创建一个矩阵。
# If you want to be specific, you can set the dtype (see below) at creation time |
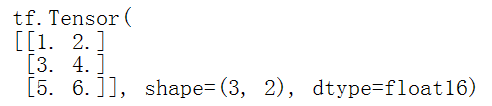
标量、向量、矩阵的对比。

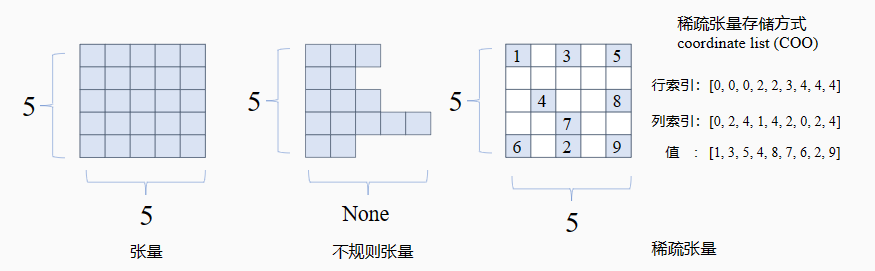
张量有一些特殊的情况,比如不规则张量和稀疏张量等。
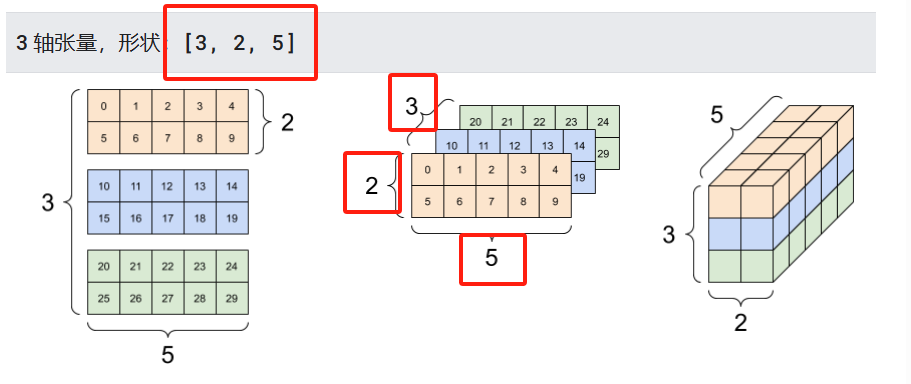
张量的轴可以更多,下面是一个包含3个轴的张量。
# There can be an arbitrary number of |
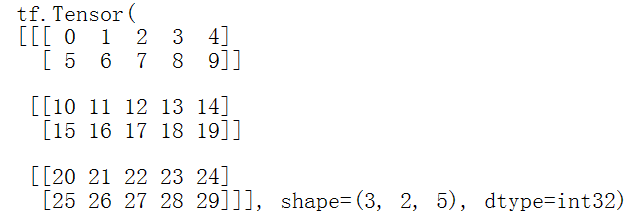
两个轴以上的张量,会用熟悉的张量图来表示。
张量和NumPy数组类似,通过使用np.array()或者tensor.numpy()方法可以把张量转化成NumPy数组。
#方法1 |
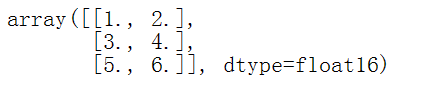
#方法2 |
张量一般是浮点型和整型,也可以是复杂的数值或字符串。
tf.Tensor要求张量是规则的“矩形”,每个轴上每一个元素大小相同。当然也有不规则张量和稀疏张量的特殊类型。
张量可以执行基本的数学运算,加法、逐元素乘、矩阵乘等等。
a = tf.constant([[1, 2], |

还有一种更简单的写法,分别是+加法、*逐元素乘法、@矩阵乘法。
print(a + b, "\n") # element-wise addition |
张量还可以进行多种运算,比如:tf.reduce_max取最大值,tf.math.argmax取最大值索引,tf.nn.softmax归一化。
c = tf.constant([[4.0, 5.0], [10.0, 1.0]]) |

在tensorflow中,需要作为张量输入的任何地方,都可以使用tf.convert_to_tensor()函数把数组转为tensor类型。
tf.convert_to_tensor([1,2,3]) |
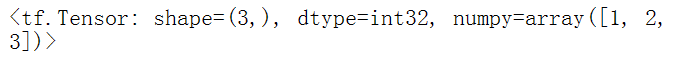
算子 Operator
深度学习中的算子是指用于执行各种数学运算和操作的函数或类,算子常常用在构建神经网络各个层和组件,用于实现数据(张量)的传递、转换和计算。
常见的算子有:卷积算子、池化算子和激活函数算子。
卷积算子:通过在数据上滑动的卷积核计算每个位置的加权和,不同的卷积核可以提取不同的数据特征;
池化算子:用来减少输入数据的尺寸并保留重要特征,常见的池化有最大池化和平均池化,可以选择输入数据的局部最大值或平 均值来降低维度,从而提高数据处理效率并防止过拟合;
激活函数算子:常用来对神经元的输出进行非线性变换以拟合目标值,常见的激活函数有ReLU、Sigmoid、Tanh等,激活函数 有效的提高了神经网络的拟合能力。
算子的组成有输入、计算逻辑、参数、输出。
这些算子在TensorFlow的计算图中被表示为节点node,并通过边edge与输入和输出张量tensors相连。TensorFlow提供了大量的内置算子,用于执行各种操作,比如:
数学运算:加法、减法、乘法、除法、矩阵乘法、指数、对数等。
逻辑运算:比较(大于、小于、等于)、逻辑与(AND)、逻辑或(OR)等。
数组操作:切片、连接、重塑(reshape)、排序、索引等。
神经网络层:全连接层(Dense)、卷积层(Conv2D)、池化层(MaxPooling2D)等。
损失函数和优化器:均方误差(MSE)、交叉熵损失(CrossEntropyLoss)、梯度下降优化器(SGD)等。
一个简单的TensorFlow示例,展示如何使用算子来执行加法运算,结果返回一个张量。
import tensorflow as tf |
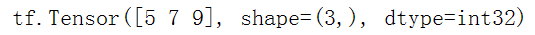
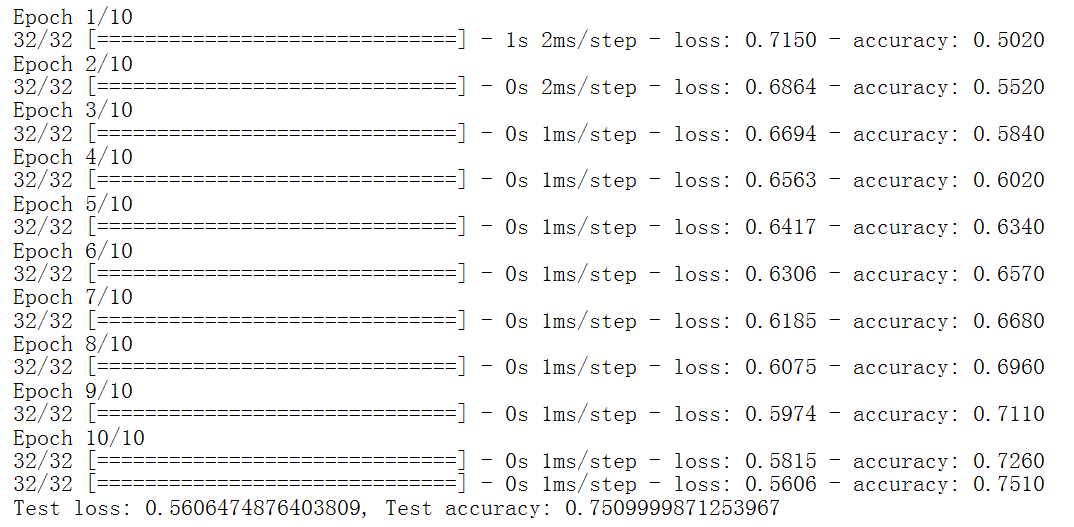
找到一个稍微复杂的神经网络例子来体会tensorflow的算子和张量,以及认识一下代码。
# 导入TensorFlow库 |
计算图 Graph
非常好的参考文档4. 计算图 — 机器学习系统:设计和实现 1.0.0 documentation (openmlsys.github.io)。
机器学习程序如何高效地在硬件上执行?这一问题又能被进一步拆解为:如何对机器学习程序描述的模型进行调度和执行?如何使模型调度执行更高效?如何自动计算并更新模型所需的梯度?解决这些问题的关键是计算图Graph技术。
早期机器学习框架主要针对全连接和卷积神经网络设计,这些神经网络的拓扑结构简单,神经网络层之间通过串行连接。现代机器学习模型的拓扑结构日益复杂(例如带有分支的循环结构等)需要机器学习框架能够对模型算子执行的依赖关系、梯度计算以及训练参数进行快速高效的分析,以便于优化模型结构、制定调度策略、自动化梯度计算等,从而提高训练大模型的效率,基于计算图的机器学习框架应运而生。
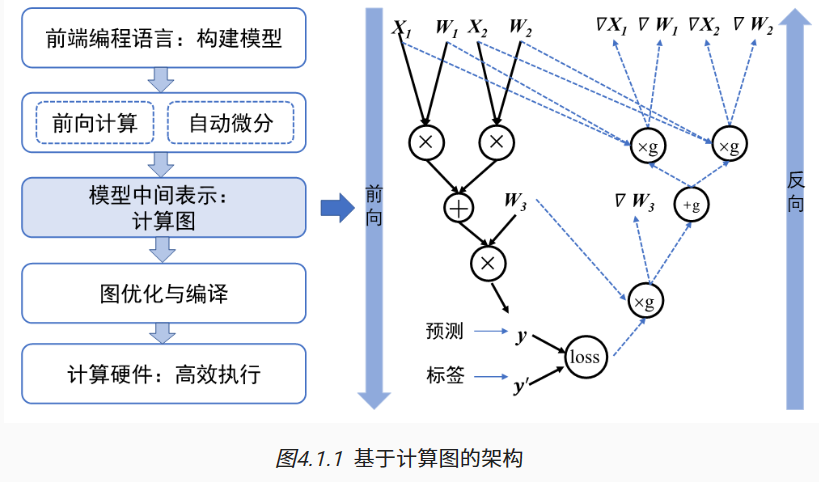
计算图的基本组成
计算图由基本数据结构张量(Tensor)和基本运算单元算子构成。在计算图中通常使用节点来表示算子,节点间的有向边(Directed Edge)来表示张量状态,同时也描述了计算间的依赖关系。
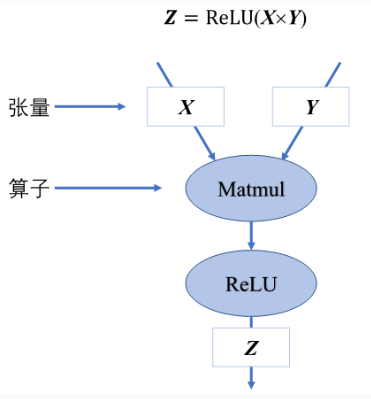
计算依赖
在计算图中,算子之间存在依赖关系,而这种依赖关系影响了算子的执行顺序与并行情况。
计算图是一个有向无环图,即在计算图中不允许出现循环依赖的数据流向。
依赖关系可以分为:直接依赖、简介依赖和相互独立。
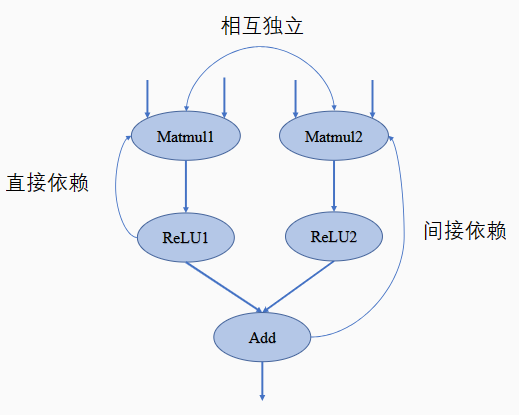
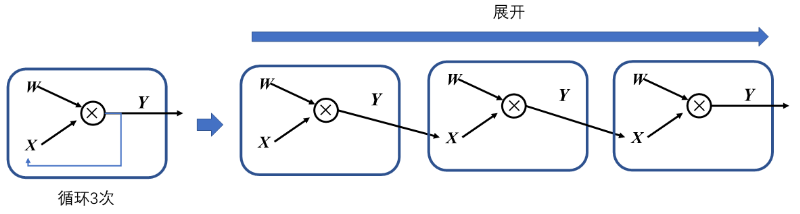
在机器学习框架中,表示循环关系(Loop Iteration)通常是以展开机制(Unrolling)来实现,以避免出现死循环。
控制流
控制流能够设定特定的顺序执行计算任务,帮助构建更加灵活和复杂的模型。
目前主流的机器学习框架中通常使用两种方式的控制流:前端语言控制流和机器学习框架控制原语。
前端语言控制流:通过Python语言控制流语句来进行计算图中的控制决策,直接使用if-else、while和for这些Python命令来构建控制流。使用前端语言控制流构建模型结构简便快捷,但是由于机器学习框架的数据计算运行在后端硬件,造成控制流和数据流之间的分离,计算图不能完整运行在后端计算硬件上;
机器学习框架控制原语:机器学习框架在内部设计了低级别细粒度的控制原语运算符。如tf.cond条件控制、tf.while_loop循环控制和tf.case分支控制等来构建模型控制流,低级别控制原语运算符能够执行在计算硬件上,与模型结合使用可将整体计算图放在后端运算。
当模型中有循环控制时,循环中的操作可以执行零次或者多次。此时采用展开机制,对每一次操作都赋予独特的运算标识符,以此来区分相同运算操作的多次调用。每一次循环都直接依赖于前一次循环的计算结果,所以在循环控制中需要维护一个张量列表,将循环迭代的中间结果缓存起来,这些中间结果将参与前向计算和梯度计算。下面是一个简单的前端语言控制流的代码实例,两端代码是等效的,结合循环控制计算图一起看。
#一个带有循环的控制流语句,模拟某种简单的循环神经网络(RNN)的行为 |
下图描述了上述代码的前向计算图和反向计算图,执行循环体的梯度计算中,循环体当前迭代计算输出的梯度值作为下一次迭代中梯度计算的输入值,直至循环结束。
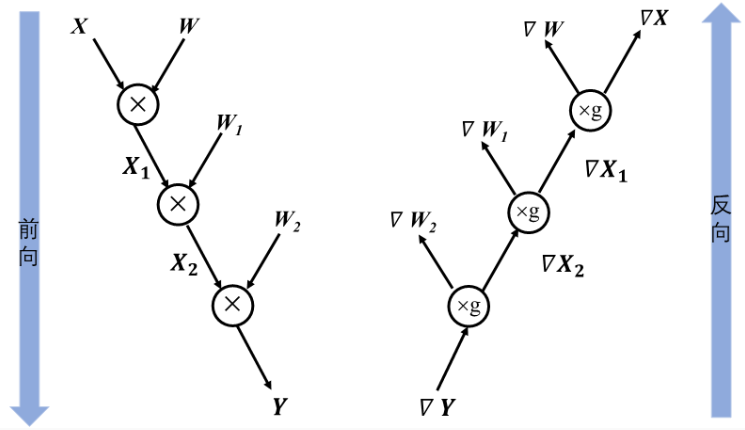
再次理解前向传递和反向传递
在深度神经网络模型训练过程中,前向传播的输出结果与标签值通过计算产生损失Loss。模型将损失Loss通过计算图反向传播,通常使用损失Loss关于参数的梯度来进行更新。
反向传播过程中,使用链式法则来计算参数的梯度信息。
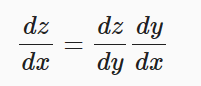
神经网络的反向传播是根据反向计算图的特定运算顺序来执行链式法则的算法。由于神经网络的输入通常为三维张量,输出为一维向量。因此将上述复合函数关于标量的梯度法则进行推广和扩展。则z关于X的每一个元素的偏导数即为:
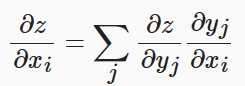
为了便于理解链式法则在神经网络模型中的运用,给出前向和反向结合的简单计算图。这个神经网络模型经过两次矩阵相乘得到预测值Y,然后根据输出与标签值之间的误差值进行反向梯度传播,以最小化误差值的目的来更新参数权重,模型中需要更新的参数权重包含W和W1。
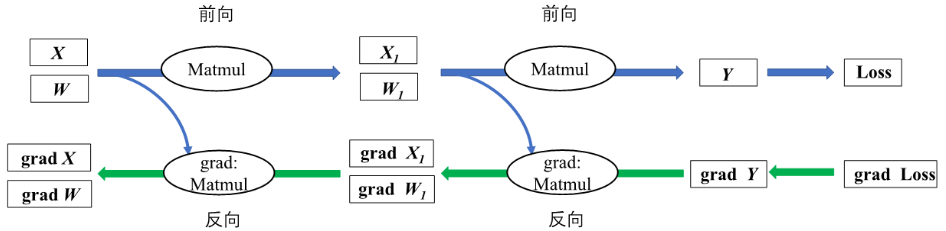
假设选取均方误差MSE为损失函数,首先通过前向传播来计算损失值三个步骤,此处Label即为标签值。
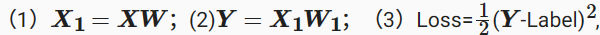
我们的目的是最小化预测值和标签值间的差异。为此根据链式法则来求解损失函数关于权重参数W和W1的梯度值。
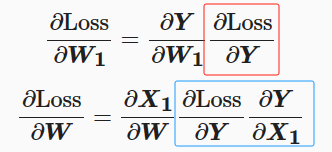
其中红框对应的就是流程图中gradY,蓝框对应的就是gradX1。接着带入上面(1)(2)(3)三个式子并化简。
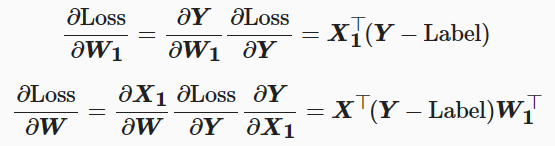
可以发现计算图在利用链式法则构建反向计算图时,会保存中间结果和梯度传递状态,通过占用部分内存来提高反向传播计算的效率。
将上述的链式法则推导推广到更加一般的情况,结合控制流的灵活构造,机器学习框架均可以利用计算图快速分析出前向数据流和反向梯度流的计算过程,正确的管理中间结果内存周期,更加高效的完成计算任务。
计算图的生成
计算图有静态生成和动态生成两种。
静态生成可以根据前端语言描述的神经网络拓扑结构以及参数变量等信息构建一份固定的计算图。因此静态图在执行期间可以不依赖前端语言描述,常用于神经网络模型的部署,比如移动端人脸识别场景中的应用等。
动态图则需要在每一次执行神经网络模型时依据前端语言描述动态生成一份临时的计算图,这意味着计算图的动态生成过程灵活可变,有助于在神经网络结构调整阶段提高效率。
主流机器学习框架TensorFlow、MindSpore均支持动态图和静态图模式;PyTorch则可以通过工具将构建的动态图神经网络模型转化为静态结构,以获得高效的计算执行效率。
| 特性 | 静态图 | 动态图 |
|---|---|---|
| 即时获取中间结果 | 否 | 是 |
| 代码调试难易 | 难 | 易 |
| 控制流实现方式 | 特定的语法 | 前端语言语法 |
| 性能 | 优化策略多,性能更佳 | 图优化受限,性能较差 |
| 内存占用 | 内存占用少 | 内存占用相对较多 |
| 内存占用 | 可直接部署 | 不可直接部署 |
动态图便于调试,适用于模型构建实验阶段;静态图执行高效,节省模型训练时间。目前TensorFlow、MindSpore、PyTorch等主流机器学习框架为了兼顾动态图易用性和静态图执行性能高效两方面优势,均具备动态图转静态图的功能,支持使用动态图编写代码,框架自动转换为静态图网络结构执行计算。
动态图转换为静态图的实现方式有两种:
基于追踪转换:以动态图模式执行并记录调度的算子,构建和保存为静态图模型。
基于源码转换:分析前端代码来将动态图代码自动转写为静态图代码,并在底层自动帮用户使用静态图执行器运行。
| 框架 | 动态图转静态图 |
|---|---|
| TensorFlow | @tf_function追踪算子调度构建静态 图,其中AutoGraph机制可以自动转换控制流为静态表达 |
| MindSpore | contex t.set_context(mode=context.PYNATIVE_MODE)动态图模式,context.set_context(mode=context.GRAPH_MODE) 静态图模式,@ms_function支持基于源码转换 |
| PyTorch | torch.jit.script()支 持基于源码转换,torch.jit.trace()支持基于追踪转换 |
计算图的调度
模型训练就是计算图调度图中算子的执行过程。宏观来看训练任务是由设定好的训练迭代次数来循环执行计算图,此时需要优化迭代训练计算图过程中数据流载入和训练(推理)执行等多个任务之间的调度策略。微观上单次迭代需要考虑计算图内部的调度执行问题,根据计算图结构、计算依赖关系、计算控制分析算子的执行调度。优化计算图的调度和执行性能,目的是尽可能充分利用计算资源,提高计算效率,缩短模型训练和推理时间。
根据任务队列的执行顺序,我们可以将计算图的任务调度队列分为以下两种:
串行:队列中的任务必须按照顺序进行调度执行直至队列结束;
并行:队列中的任务可以同时进行调度执行,加快执行效率。
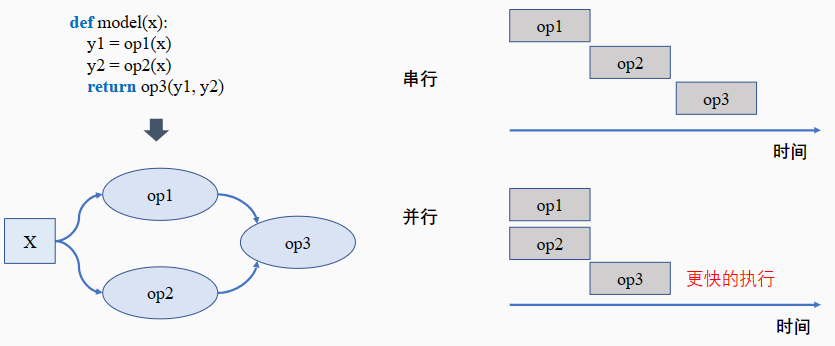
一次完整计算图的训练执行过程包含:数据载入、数据预处理、网络训练三个环节。三个环节之间的任务调度是以串行方式进行,每一个环节都有赖于前一个环节的输出。但计算图的训练是多轮迭代的过程,多轮训练之间的三个环节可以用同步与异步两种机制来进行调度执行。
同步:顺序执行任务,当前任务执行完后会等待后续任务执行情况,任务之间需要等待、协调运行;
异步:当前任务完成后,不需要等待后续任务的执行情况,可继续执行当前任务下一轮迭代。
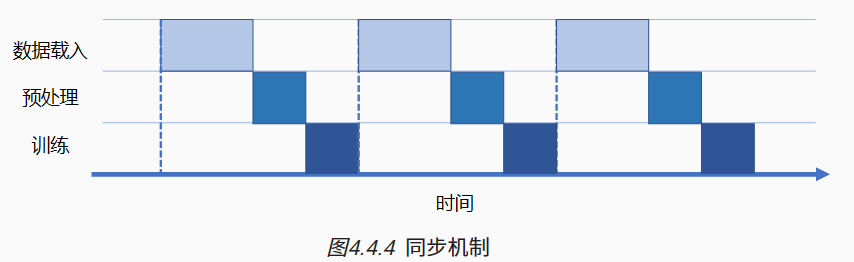
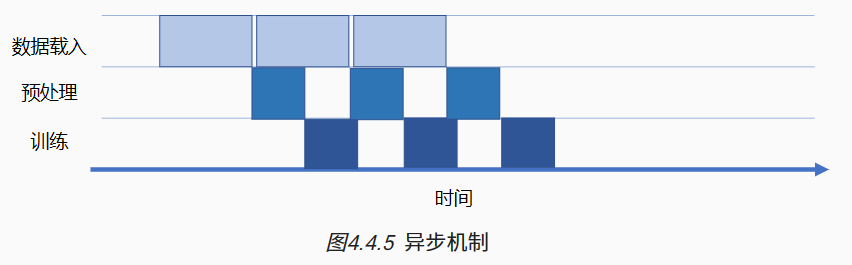
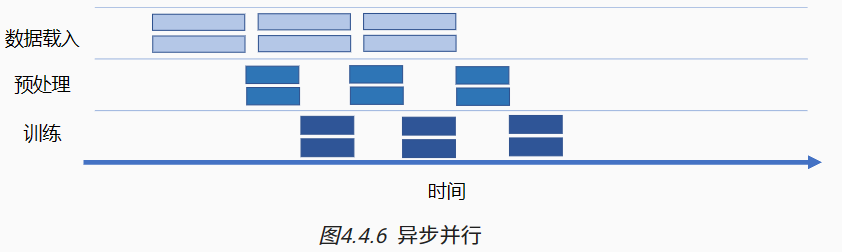
会话 Session
在TensorFlow中,会话(Session)是一个核心概念,会话提供了执行计算图(Graph)的环境。
会话是TensorFlow中用于执行计算图(Graph)的接口。计算图是由节点(Node)和边(Edge)组成的网络,其中节点代表操作(Operation),边代表张量(Tensor)之间的数据流。
在TensorFlow中,计算图必须在会话中运行。会话可以跨多个CPU和GPU进行分布式运算,这有助于充分利用硬件资源,加速计算过程。
会话的功能和作用
执行计算图:会话将计算图转化为不同设备上的执行步骤,从而实际执行图中的操作。
资源分配与管理:会话不仅负责运行图结构,还负责分配资源进行计算,并管理这些资源,如变量的资源、队列和线程等。通过会话,TensorFlow可以有效地利用硬件资源,确保计算任务的顺利执行。
桥接前后端系统:TensorFlow分为前端系统和后端系统。前端系统主要负责定义图的结构,包括定义操作和张量等;而后端系统则负责运算图的结构,执行实际的计算任务。会话作为两者之间的桥梁,使得前端定义的图结构能够在后端得到执行。
会话的使用方式
在TensorFlow 1.x版本中,会话的创建和使用是显式的。用户需要首先创建一个会话对象(通过tf.Session()或tf.compat.v1.Session()),然后使用该会话对象的run()方法来执行计算图中的操作。
在TensorFlow 2.x版本中,引入了Eager Execution模式。在这种模式下,会话的概念变得不那么明显,因为操作会立即执行并返回结果。但是,对于需要跨多个设备或需要更精细控制资源分配的场景,仍然可以使用tf.compat.v1.Session()来创建和使用会话。
简易理解tensorflow运行架构
一个非常好的参考文章TensorFlow是什么?TensorFlow入门与实践 架构与设计详解 - 知乎 (zhihu.com)。
一个详细的参考文章《TensorFlow 内核剖析》笔记——系统架构 - 知乎 (zhihu.com)。
TensorFlow的系统架构是一个多层次、模块化的结构,它基于数据流图的概念,用于大规模分布式数值计算。
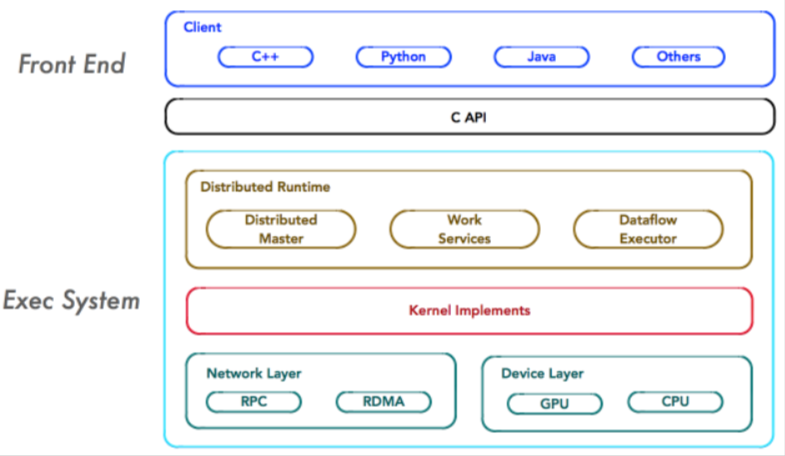
Tensorflow的系统结构以C API为界,将整个系统分为前端和后端两个子系统。前端构造计算图,后端执行计算图。
Client是前端系统的主要组成部分,它是一个支持多语言的编程环境。它提供基于计算图的编程模型,方便用户构造各种复杂的计算图,实现各种形式的模型设计。Client通过Session为桥梁,连接TensorFlow后端的”运行时“,并启动计算图的执行过程。
在分布式的运行时环境中,Distributed Master根据Session.run的Fetching参数,从计算图中反向遍历,找到所依赖的最小子图。
然后,Distributed Master负责将该最小子图再次分裂为多个子图片段,以便在不同的进程和设备上运行这些子图片段。
最后,Distributed Master将这些子图片段派发给Work Service;随后Work Service启动子图片段的执行过程。
对于每以个任务,TensorFlow都将启动一个Worker Service。Worker Service将按照计算图中节点之间的依赖关系,根据当前的可用的硬件环境(GPU/CPU),调用OP的Kernel实现完成OP的运算(一种典型的多态实现技术)。另外,Worker Service还要负责将OP运算的结果发送到其他的Work Service;或者接受来自其他Worker Service发送给它的OP运算的结果。
Kernel是OP在某种硬件设备的特定实现,它负责执行OP的运算。
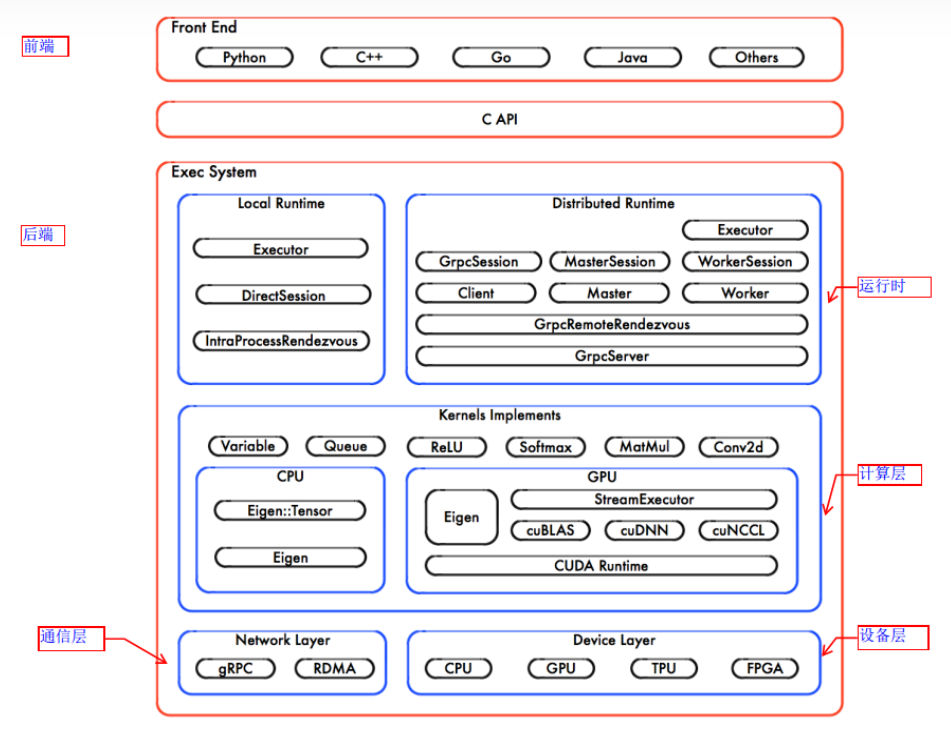
看一个更详细的架构图,后端执行计算图,可再细分为:
运行时:提供本地模式和分布式模式;
计算层:由kernal函数组成;
通信层:基于gRPC实现组件间的数据交换,能够在支持IB网络的节点间实现RDMA通信;
设备层:计算设备是OP执行的主要载体,TensorFlow支持多种异构的计算设备类型。
实现一个基于tensorflow的简易深度学习框架
import tensorflow as tf |

对于这个代码例子,主要在于熟悉流程和函数。基本流程是:加载和预处理MNIST数据集-实例化模型-训练模型-评估模型-进行预测。










