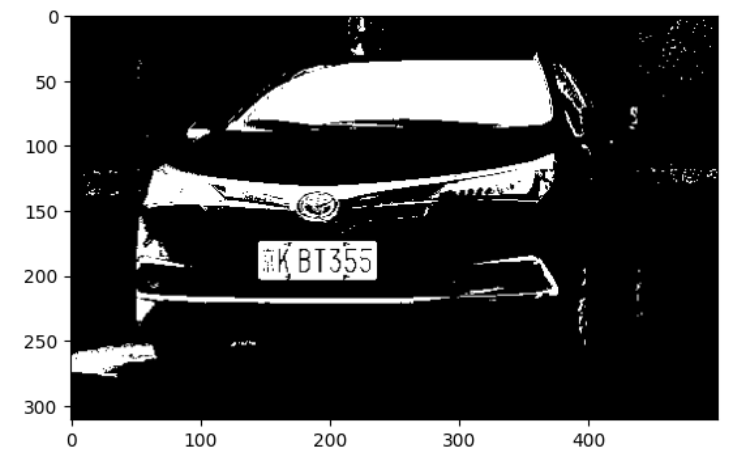
Python-OpenCV车牌识别简易版(2) 接上文,现在车牌的部分已经很清晰了,我们把车牌的部分的轮廓提取出来。
contours,hierarchy = cv2.findContours(image,cv2.RETR_EXTERNAL,cv2.CHAIN_APPROX_SIMPLE) image1= rawImage.copy() cv2.drawContours(image1,contours,-1 ,(0 ,0 ,255 ),5 ) plt_show0(image1)
【9】轮廓检测 contours,hierarchy =cv2.findContours(image,mode,method)
cv2.findContours()函数可以从二值图像中提取轮廓,并返回一个包含轮廓信息的列表和一个包含轮廓层次结构的numpy数组。
mode: 轮廓检索模式,决定了返回的轮廓列表中包含哪些轮廓。有四种模式可选:
cv2.RETR_EXTERNAL: 只返回最外层的轮廓,忽略内部的轮廓;cv2.RETR_LIST: 返回所有的轮廓,不建立任何层次关系;cv2.RETR_CCOMP: 返回所有的轮廓,并将它们组织成两层结构,顶层是外部轮廓,次层是内部轮廓;cv2.RETR_TREE: 返回所有的轮廓,并建立一个完整的轮廓层次结构,可以表示图像中任意嵌套的轮廓。
method: 轮廓近似方法,决定了返回的轮廓点的数量和位置。有两种方法可选:
cv2.CHAIN_APPROX_NONE: 返回轮廓上的所有点,不做任何近似。cv2.CHAIN_APPROX_SIMPLE: 只返回轮廓上的拐点,去除冗余的点,例如一条直线上的点。
cv2.drawContours(image1,contours,-1,(0,0,255),5)
contours必须是一个由点坐标组成的数组。
这个系统兼顾了蓝色车牌和绿色车牌的识别,所以我们先设定关于颜色的掩膜。
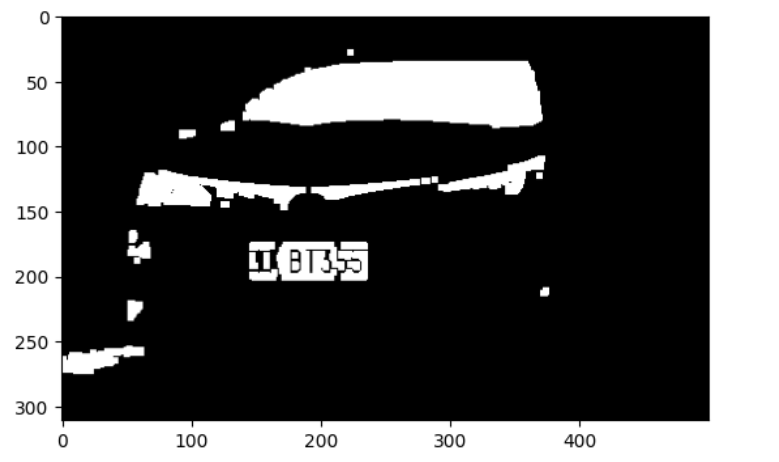
image2= rawImage.copy() hsv = cv2.cvtColor(image2, cv2.COLOR_BGR2HSV) lower_blue = (100 , 43 , 46 ) upper_blue = (124 , 255 , 255 ) lower_green = (35 , 43 , 46 ) upper_green = (77 , 255 , 255 ) mask_blue = cv2.inRange(hsv, lower_blue, upper_blue) mask_green = cv2.inRange(hsv, lower_green, upper_green) plt_show(mask_blue) plt_show(mask_green)
【10】mask = cv2.inRange(image, lower, upper)
inRange()用于提取图像中指定颜色范围内的像素。
cv2.inRange函数的作用是根据指定的下限和上限阈值,将输入图像中的像素值限制在这个范围内。它会将满足条件的像素设置为255(白色),不满足条件的像素设置为0(黑色),从而形成一个二值图像。这种二值图像常用于图像分割、目标提取等任务中。
上图还是有很多噪音和孔洞,我们利用开运算,让图片更加有效和紧凑。
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (5 , 5 )) mask_blue = cv2.morphologyEx(mask_blue, cv2.MORPH_OPEN, kernel) mask_green = cv2.morphologyEx(mask_green, cv2.MORPH_OPEN, kernel) plt_show(mask_blue) plt_show(mask_green)
得到两个掩膜后将其合并。
mask = cv2.bitwise_or(mask_blue, mask_green) filtered = cv2.bitwise_and(image2, image2, mask=mask) plt_show0(filtered)
现在车牌已经非常明显了,我们可以按照轮廓面积、矩形的长款比、矩形和轮廓的覆盖率、矩形和掩膜的覆盖率等来筛选出车牌所在的区域。
plates = [] for contour in contours: area = cv2.contourArea(contour) x, y, w, h = cv2.boundingRect(contour) ratio = w / h if ratio < 2 or ratio > 6 : image_pass = image2[y:y+h,x:x+w] plt_show(image_pass) print ('长宽不通过' ) continue rect_area = w * h coverage = area / rect_area if coverage < 0.5 : image_pass = image2[y:y+h,x:x+w] plt_show(image_pass) print ('矩形和轮廓的覆盖率不通过' ) continue mask_area = cv2.countNonZero(mask[y:y+h, x:x+w]) mask_coverage = mask_area / rect_area if mask_coverage < 0.5 : image_pass = image2[y:y+h,x:x+w] plt_show(image_pass) print ('掩膜覆盖率不通过' ) continue plates.append((x, y, w, h)) if len (plates) == 0 : print ("No plates found." ) elif len (plates) > 1 : print ("Multiple plates found." ) else : x, y, w, h = plates[0 ] cv2.rectangle(image2, (x, y), (x+w, y+h), (0 , 255 , 0 ), 1 ) plt_show0(image2) image3 = image2[y:y+h,x:x+w] cv2.imwrite('./car_license/test1.png' ,image3)
【11】计算面积area = cv2.contourArea(contour, oriented = False)
contour 表示输入的单个轮廓,是一个由点坐标组成的数组。
cv2.contourArea函数的作用是根据轮廓的点坐标,使用格林公式计算轮廓的面积,格林公式是一个将平面曲线积分转化为沿曲线的线积分的公式。
【12】最小外接矩形 x, y, w, h = cv2.boundingRect(contour)
contour 表示输入的单个轮廓,是一个由点坐标组成的数组,可以使用OpenCV的findContours函数获取。
x, y, w, h 表示输出的矩形的左上角坐标 (x, y) ,以及宽度 w 和高度 h 。
cv2.boundingRect函数的作用是根据轮廓的点坐标,找到一个能够包围轮廓的最小矩形。这个矩形是水平的,不会发生旋转。
如果想要找到一个可能旋转的最小矩形,可以使用cv2.minAreaRect函数。
【13】统计图像非零像素的个数count = cv2.countNonZero(src)
例子:结合掩膜可以统计任何颜色的数目
hsv = cv2.cvtColor(image, cv2.COLOR_BGR2HSV) #定义蓝色的颜色范围
lower_blue = np.array([100, 50, 50]) # 下界阈值
upper_blue = np.array([130, 255, 255]) # 上界阈值 #应用颜色范围阈值
mask_blue = cv2.inRange(hsv, lower_blue, upper_blue) #统计非零像素值的个数
count = cv2.countNonZero(mask_blue)
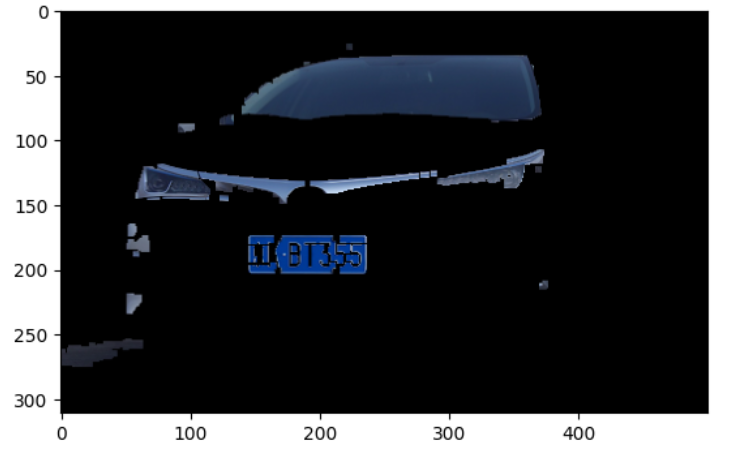
第2章 车牌字符分割 先看看提取出来的车牌。
license = cv2.imread('./car_license/test1.png' ) plt_show0(license)
还是老规矩,先高斯去噪,再转为灰度,再阈值化。
licence_GB = cv2.GaussianBlur(license,(1 ,3 ),0 ) plt_show0(licence_GB) licence_gray = cv2.cvtColor(licence_GB,cv2.COLOR_BGR2GRAY) plt_show(licence_gray) ret , img = cv2.threshold(licence_gray,0 ,255 ,cv2.THRESH_OTSU) plt_show(img)
kernel = cv2.getStructuringElement(cv2.MORPH_RECT,(2 ,1 )) img_close = cv2.dilate(img,kernel) plt_show(img_close) number_contours , hierarchy = cv2.findContours(img_close,cv2.RETR_EXTERNAL,cv2.CHAIN_APPROX_SIMPLE) img1 = license.copy() cv2.drawContours(img1,number_contours,-1 ,(0 ,255 ,0 ),1 ) plt_show0(img1)
然后根据轮廓的位置和大小进行筛选,并分割处每个字符。
chars = [] for cnt in number_contours: x, y, w, h = cv2.boundingRect(cnt) if w < 5 or h < 10 or w > 50 or h > 50 : continue ratio = w / h if ratio < 0.25 or ratio > 0.7 : continue chars.append((x, y, w, h)) chars = sorted (chars, key=lambda x: x[0 ]) print (chars)i = 0 for x, y, w, h in chars: i = i+1 char = license[y:y+h, x:x+w] char = cv2.resize(char, (64 , 64 )) plt_show(char) cv2.imwrite('./words/test2_' +str (i)+'.png' ,char)
至此,我们就可以看到每一个字符都被分割了出来,下一章,我们进行模式匹配来按顺序识别字符。