
人工智能入门10-华为昇腾实习笔记-从0到1制作自定义镜像并用于训练(PyTorch+CPU/GPU)
5.31学习:
- 完成实践《从0到1制作自定义镜像并用于训练(PyTorch+CPU/GPU)》
- 官方案例小总结
《从0到1制作自定义镜像并用于训练(PyTorch+CPU/GPU)》
本教程引导从0到1制作镜像,并使用该镜像在ModelArts平台上进行训练。镜像中使用的AI引擎是PyTorch,训练使用的资源是CPU或GPU。使用Linux x86_64架构的主机,操作系统ubuntu-18.04,通过编写Dockerfile文件制作自定义镜像。
所需镜像环境:ubuntu-18.04+cuda-11.1+python-3.7.13+pytorch-1.8.1。
创建OBS桶和文件夹
打开OBS控制台,创建桶和文件夹。
| 文件夹路径和名字 | 用途 |
|---|---|
| obs://test-bucket-xiaowang/pytorch/demo-code | 用于存储训练脚本文件。 |
| obs://test-bucket-xiaowang/pytorch/log | 用于存储训练日志文件。 |
准备训练脚本并上传至OBS
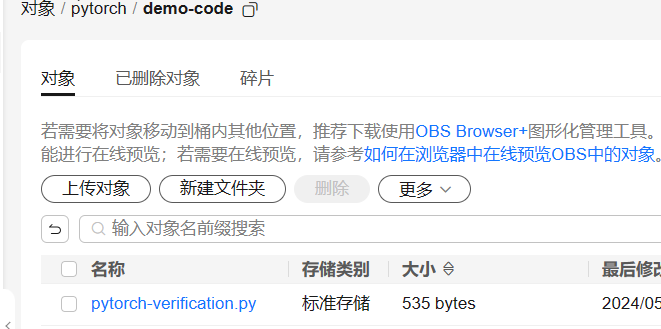
准备本案例所需的训练脚本【pytorch-verification.py】文件,并上传至OBS桶的obs://test-bucket-xiaowang/pytorch/demo-code文件夹下。
pytorch-verification.py文件内容如下。
import torch |
准备镜像主机
利用上一章节构建的ECS实例x86计算-Ubuntu18.04即可。
制作自定义镜像
上一章节已经安装好docker,这里就不用安装了。
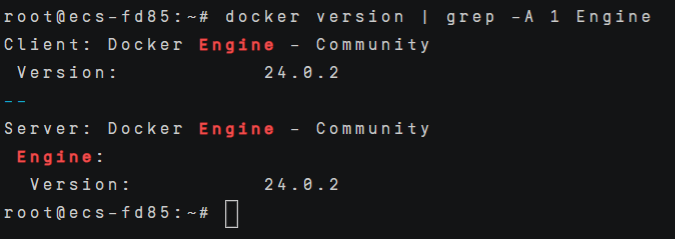
执行如下命令确认Docker Engine版本。
docker version | grep -A 1 Engine |
创建名为context的文件夹。
mkdir -p context |
进入文件夹,并新建pip.conf文件作为pip源文件。
cd context |
按i键进入编辑模式,复制以下内容。
[global] |
按ESC退出编辑模式,输入:wq保存退出。
在context文件夹中从网站https://download.pytorch.org/whl/torch_stable.html上下载三个torch*.whl 文件,再下载Miniconda3安装文件。下载链接如下。
https://download.pytorch.org/whl/cu111/torch-1.8.1%2Bcu111-cp37-cp37m-linux_x86_64.whl
https://download.pytorch.org/whl/torchaudio-0.8.1-cp37-cp37m-linux_x86_64.whl
https://download.pytorch.org/whl/cu111/torchvision-0.9.1%2Bcu111-cp37-cp37m-linux_x86_64.whl
https://repo.anaconda.com/miniconda/Miniconda3-py37_4.12.0-Linux-x86_64.sh
wget https://download.pytorch.org/whl/cu111/torch-1.8.1%2Bcu111-cp37-cp37m-linux_x86_64.whl | wget https://download.pytorch.org/whl/torchaudio-0.8.1-cp37-cp37m-linux_x86_64.whl | wget https://download.pytorch.org/whl/cu111/torchvision-0.9.1%2Bcu111-cp37-cp37m-linux_x86_64.whl | wget https://repo.anaconda.com/miniconda/Miniconda3-py37_4.12.0-Linux-x86_64.sh |
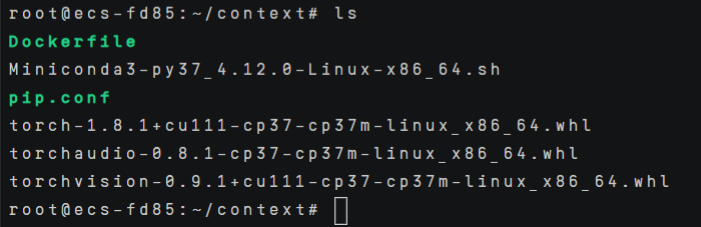
下载需要一些时间,完成后,ls查看context文件夹内容,应该如下所示。

在context文件夹内新建名为Dockerfile的空文件,作为容器镜像文件。
touch Dockerfile |
复制进去以下内容然后保存。
# 容器镜像构建主机需要连通公网 |
此时context文件夹的结构应该是:
context |
在Dockerfile文件所在的目录执行如下命令构建容器镜像pytorch:1.8.1-cuda11.1。
docker build . -t pytorch:1.8.1-cuda11.1 |
这一步也需要一些时间,最后出现Successfully tagged pytorch:1.8.1-cuda11.1说明成功。
上传镜像至SWR服务
登录容器镜像服务-控制台 (huaweicloud.com),注意区域要和ModelArts区域保持一致。
单击右上角【创建组织】,输入组织名称ai_wang完成组织创建。
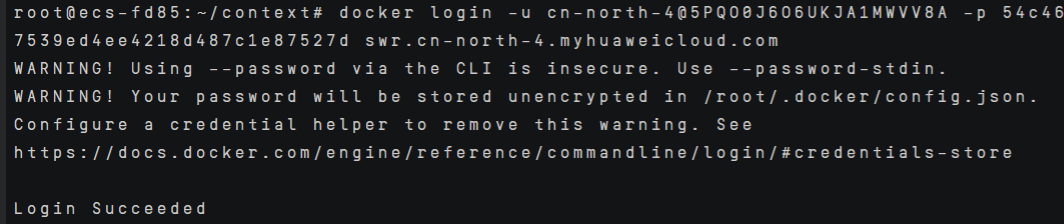
单击右上角【登录指令】,选择复制临时登录指令,复制到ECS实例中运行。
docker login -u cn-north-4@EQVIKLYSGZNPUUI7E1R6 -p 64144bf0b5562702c9df4cd9480e9c0c23e10ad255e9ddbcf28b05c699d320b8 swr.cn-north-4.myhuaweicloud.com |
使用docker tag命令给上传镜像打标签。
#swr.cn-north-4.myhuaweicloud.com请替换为实际值,组织名称ai_wang也请替换为自定义的值。 |
使用docker push命令上传镜像,这一步需要一些时间。
#swr.cn-north-4.myhuaweicloud.com请替换为实际值,组织名称ai_wang也请替换为自定义的值。 |
完成镜像上传后,在容器镜像服务控制台的【我的镜像】页面可查看已上传的自定义镜像。

在ModelArts上创建训练作业
登录ModelArts管理控制台,在左侧导航栏中选择【训练管理】-【训练作业】,默认进入训练作业列表。在【创建训练作业页面】,如图所示填写相关参数,然后单击【提交】。
创建方式:选择【自定义算法】;
启动方式:选择【自定义】;
镜像地址:选择刚刚创建的镜像【swr.cn-north-4.myhuaweicloud.com/ai_wang/pytorch:1.8.1-cuda11.1】;
代码目录:设置为OBS中存放启动脚本文件的目录,例如:obs://test-bucket-xiaowang/pytorch/demo-code/,训练代码会被自动下载至训练容器的${MA_JOB_DIR}/demo-code目录中,demo-code为OBS存放代码路径的最后一级目录,可以根据实际修改。
启动命令:/home/ma-user/miniconda3/bin/python ${MA_JOB_DIR}/demo-code/pytorch-verification.py,此处的demo-code为用户自定义的OBS存放代码路径的最后一级目录,可以根据实际修改。
资源池:选择公共资源池
类型:选择GPU或者CPU规格。
永久保存日志:打开
作业日志路径:设置为OBS中存放训练日志的路径。例如:obs:// /test-bucket-xiaowang/pytorch/log/

训练作业创建完成后,后台将自动完成容器镜像下载、代码目录下载、执行启动命令等动作。
训练作业执行成功后,日志信息如下所示。

清除资源和数据
清除训练作业;
删除本地镜像;
删除SWR中保存的镜像和组织;
删除OBS桶和文件;
关闭或释放ECS实例。
官方案例小总结
| 案例 | 过程描述 | 意义 |
|---|---|---|
| 《免费体验:一键完成商超商品识别模型部署》 | 1、授权:要让ModelArts的某个用户具有访问OBS、SWR等服务的权限。我们给【所有用户】都新增了【普通用户】的权限,能完成AI开发的必要功能。 2、从AI Gallery订阅了目标模型,自动放到了ModelArts控制台的【AI应用】中 3、AI应用是可以部署上线,成为在线服务的,我们选择【AI应用来源】为【我的订阅】,并选择资源池后就可以上线运行 4、上线运行的AI应用变成在线服务,可以根据这个应用的目的来【预测】等,也可以用接口来远程调用结果 5、结束后要暂停删除【在线应用】,删除【AI应用】,删除【我的订阅】 |
初次体验了从AI Gallery订阅部署模型的流程 |
| 《垃圾分类(使用新版自动学习实现图像分类)》 | 1、建立【OBS桶】来存放训练数据,以此来和ModelArts数据沟通 2、通过AI Gallery下载【ModelArts数据集】到OBS,这种类型需要指定数据集训练【input】和【output】的位置 3、进入Model Arts控制台创建【自动学习】项目,这里要选择对应数据集的输入输出路径 4、运行workflow工作流,ModelArts回自动学习,完成【数据标注】到【部署上线】的全流程,期间需要进行两次确认 5、结束后释放所有用到的资源 |
体验了ModelArts提供的自动学习功能和workflow全流程 |
| 《使用自定义算法构建模型(手写数字识别)》 | 1、准备【本地训练数据】(Minist数据集、train.py训练文件、customize_service.py推理文件和config.json推理配置) 2、创建【OBS桶】,上传所有本地文件到云端,注意OBS的文件结构有data、code(-infer)、output 3、创建【训练作业】,这次从【自定义算法】,启动方式选择预置框架,代码目的、启动文件选择刚刚OBS中的位置,输入输出新增参数并定位到OBS,然后选择资源池训练 4、训练完后要推理部署,在【AI应用】中创建,来源选择【从训练中选择】,选择刚刚的训练作业,并选定AI引擎和资源池就可以推理部署为在线应用【问题推理是AI作业变成AI应用的过程吗?】 5、预测结果,可以上传图片预测结果,最后记得释放所有资源 |
体验了把自定义算法和数据集借助ModelArts训练推理的过程 |
| 《口罩检测(使用新版自动学习实现物体检测应用)》 | 和《垃圾分类(使用新版自动学习实现图像分类)》类似 | 再次熟悉了ModelArts提供的自动学习功能和workflow全流程 |
| 《使用AI Gallery的订阅算法实现花卉识别》 | 1、从AI Gallery订阅数据集,这次选择存储为【OBS】 2、从AI Gallery订阅算法,订阅到ModelArts的【算法管理】中 3、使用订阅的算法对OBS中数据进行训练,并指定输出,选择训练池,期间还可以进行【超参调优】 4、创建AI应用,来源选择【从训练中选择】,然后推理部署 5、这个需要手动部署为【在线服务】,部署上线后即可【预测】,最后记得释放所有资源 |
再次体验了从AI Gallery订阅算法、数据,到训练完成部署上线的全流程 |
| 《使用算法套件快速完成水表读数识别》 | 1、创建OBS,从AI Gallery订阅分割和OCR两个数据集 2、创建【NoteBook】开发环境 3、在NoteBook中从OBS复制数据集过来,下载官方的两个【算法套件】,【修改代码】适配分割和识别任务,在NoteBook本地执行训练-推理的全过程,验证成功后,把这个算法导出为【模型】 4、先在NoteBook【本地部署】然后【在线部署】 5、之后就可以预测了,自动上传土拍你然后读分割识别,最后记得清除所有资源 |
体验到较为实际的"需求-数据-代码-训练-推理-上线"的AI开发全流程。 |
| 《从0-1制作自定义镜像并创建AI应用》 | 1、购买合适的【ECS】,在上面安装【docker】,编写自定义镜像文件Dockerfile和代码test_app.py 2、在本地启动并【验证镜像】,没问题后在【SWR】上传镜像托管 3、创建AI应用,来源选【从容器镜像中选择】,选择镜像所在的位置和配置调用接口,并配置apis 4、部署为【在线应用】然后实验代码,最后释放所有资源 |
体验到了自定义Docker镜像并在ModelArts部署运行的全流程 |
| 《从0到1制作自定义镜像并用于训练(PyTorch+CPU/GPU)》 | 和《从0-1制作自定义镜像并创建AI应用》类似 | 再次熟悉了自定义镜像到在ModelArts部署运行的全流程 |










