人工智能入门11-华为昇腾实习笔记-人工智能概述、机器学习概述、机器学习整体流程
从今天开始,进入到系统的理论学习,跟着华为人才在线的HCIA-AI官方课程课程详情 (huawei.com)学习并记录笔记。
课程目标:
1、了解人工智能的相关概念;
2、了解华为在人工智能方面的战略布局与华为云EI;
3、了解华为昇腾系列产品;
4、掌握初步利用华为云服务管理数据集,训练模型,部署模型的能力;
5、对MindSpore框架有基础的了解,可以实现简单应用;
6、对图像识别、图像分类、语音识别有基础的了解,有调用SDK包实现相应功能的能力;
7、对解决分类型任务,了解从数据获取、处理,模型搭建到结果输出、评估的全流程。
6.6-6.7学习:
- 观看华为人才在线HCIA-AI课程《第一章-人工智能概览》
- 观看华为人才在线HCIA-AI课程《第二章-机器学习概览》(第1节-第4节)
人工智能概览
本章首先介绍了人工智能的定义、人工智能的发展史,接着描述了人工智能的热门领域与应用场景,同时对华为的人工智能发展战略做了简要介绍,最后讨论了人工智能的争议话题和人工智能的发展趋势。
人工智能概述
艾伦·图灵、约翰·麦卡锡、马文·闵斯基三位被称为人工智能之父。
人工智能(Artificial Intelligence)的定义可以分为两部分,即“人工”和“智能”。“人工”即由人设计,由人创造,为人服务。“智能”是模拟人类智能行为,像人一样思考。人工智能是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学。
机器学习是一种实现人工智能的方法,深度学习是一种实现机器学习的技术。
机器学习主要基于样本数据构建模型,以便能在没有明确编码的情况下做出判断和预测。
深度学习的概念源自人工神经网络的研究,深度学习通过组合低层特征形成更加抽象的高层表示属性类别或特征,以发现数据的分布式特征表示。
人工智能的主要学派有:符号主义、连接主义、行为主义。
-符号主义认为人类的认知的基本单元是符号,认知过程是符号进行推理运算的过程。
-连接主义从神经元开始研究神经网络模型和脑模型,1986年多层网络反向传播算法(BP网络算法)的提出是连接主义的里程碑事件。
-行为主义偏向于应用实践,从环境不断学习以不断修正动作。
1956年达特茅斯会议提出“人工智能”概念,这一年是人工智能元年。
人工智能可以分为强人工智能和弱人工智能,强人工智能中机器是有知觉和自我意识的,弱人工智能的机器并不真正拥有智能,也不拥有自主意识。当前我们处于弱人工智能阶段。
人工智能落地的四要素是:数据、算法、算力、场景。
人工智能领域
中国人工智能企业的十大应用技术领域中,计算机视觉、机器人、自然语言处理、机器学习、生物识别占比居前五。
其中,自然语言处理的应用场景有:
-舆情分析:通过关键词提取、文本聚类、主题挖掘等算法模型,挖掘突发事件的舆论导向,进行话题发现、趋势发现、舆情分析等;
-情感分析:通过情感分析、观点抽取等相关技术从大量用户评论中提取出情感倾向以及关键的观点信息;
-知识图谱:通过NLP技术辅助进行知识抽取。比如,对一些医学材料从英文到中文,文本挖掘,一段话提炼中心思想等。
华为人工智能发展战略

CANN:芯片算子库和高度自动化算子开发工具。

MindSpore:支持端、边、云独立的和协同的统一训练和推理框架。
ModelArts :面向开发者的一站式 AI 开发平台。

MindX:昇腾应用使能。

MindX DL昇腾深度学习组件:支持 Atlas 800 训练服务器、Atlas 800 推理服务器的深度学习组件,提供昇腾 AI 处理器资源管理、昇腾 AI 处理器调度、分布式训练集合通信配置生成等基础功能,快速使能合作伙伴进行深度学习平台开发。
MindX Edge:轻量化的边缘计算资源管理运维,使能行业客户快速搭建边云协同推理平台。
MindX SDK:面向行业场景的完整AI开发套件,提供极简易用的API及图形界面,使能开发者以极少代码快速开发行业AI应用。
ModelZoo:为开发者提供丰富的场景化优选预训练模型,为开发者解决了模型的选型难、训练难、优化难等问题。
人工智能的争议和未来
思考:综合以上国家政策趋势,请你总结各国家对未来人工智能发展关注的核心。
核心主要是在:可信AI,AI理论发展,AI应用发展,隐私保护,基础算力发展……
机器学习概览
机器学习算法
机器学习(包括其分支深度学习)是研究“学习算法”的一门学问。“学习”是指:对于某类任务T和性能度量P,一个程序在T上以P衡量的性能随经验E而自我完善,那么我么称这个程序从经验E学习。
-任务𝑇:机器学习系统应该如何处理样本。
-性能度量𝑃:评估机器学习算法的能力,如准确率、错误率。
-经验𝐸:大部分学习算法可以被理解为在整个数据集上获取经验。但有些机器学习的算法并不是训练于一个固定的数据集上,例如强化学习等。
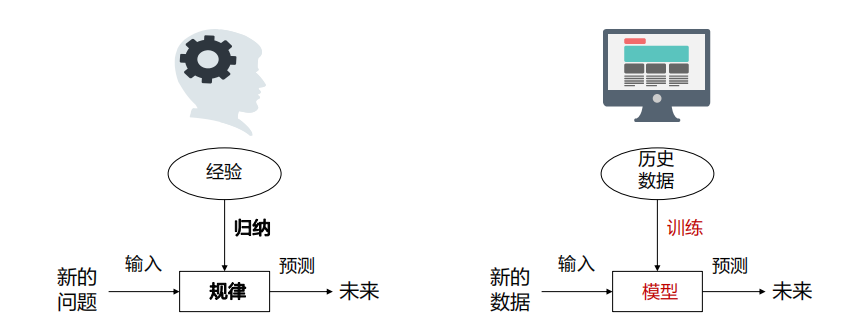
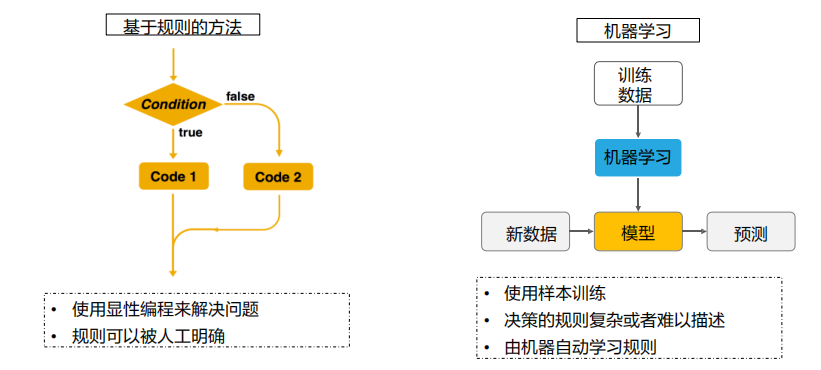
机器学习算法与传统基于规则的区别:1、传统方法使用显性编程来解决问题,且规则是被人工明确的;2、机器学习使用样本训练,且机器自动学习规则。
当问题规模大且规则又复杂的情况下可以使用机器学习算法。
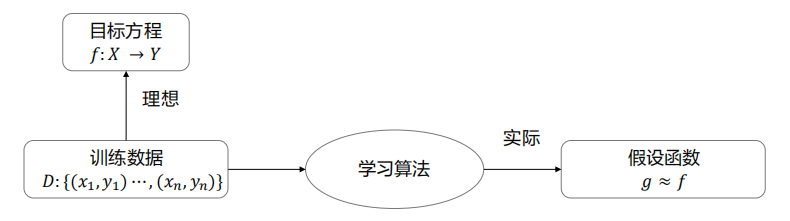
如果对机器学习算法有一个理性的认识,就是通过学习算法,从训练数据中学习到所有的特征,让假设函数不断逼近完美的目标函数。
机器学习解决的主要问题主要有三种:分类、聚类、回归。
其中,分类和回归是预测问题的两种主要类型,分类的输出是离散的类别值,而回归的输出是连续数值。
回忆:分类和聚类的区别?
机器学习的分类
机器学习可以分为四类:有监督学习、无监督学习、半监督学习、强化学习。
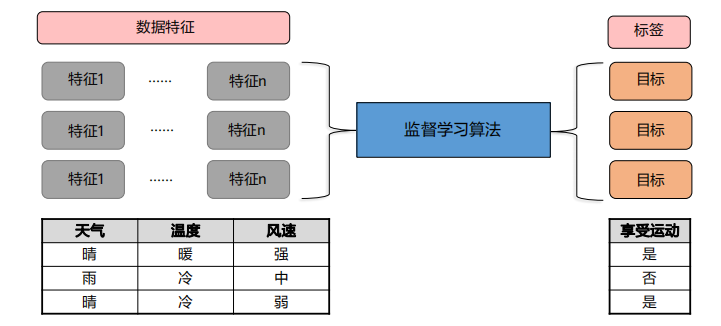
1、有监督学习:利用已知类别的样本(有标签样本),训练学习得到一个最优模型,再利用该模型将所有输入映射为输出。
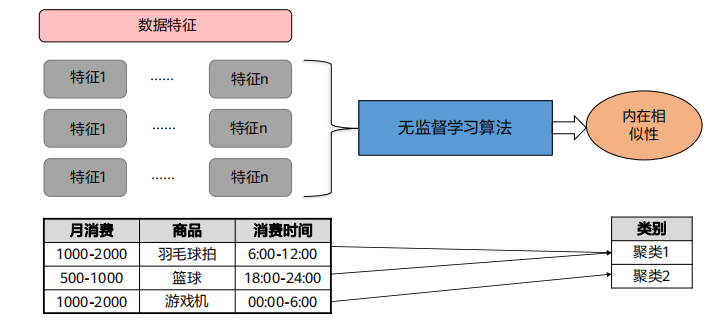
2、无监督学习:对于没有标记的样本(无标签样本),学习算法直接对输入数据进行建模,例如“聚类”。
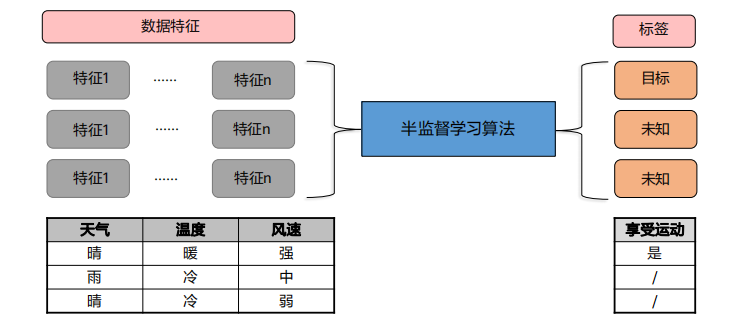
3、半监督学习:半监督学习的训练数据一部分是有标签的,另一部分是没有标签的,而没标签数据的数量常常远大于有标签数据的数量。
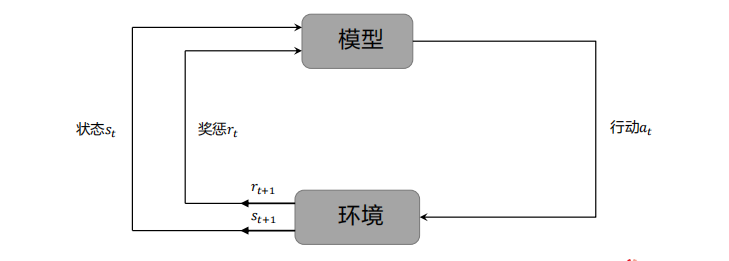
4、强化学习:学习系统从环境到行为映射的学习,以使奖励信号(强化信号)函数值最大。
有监督学习可以解决回归和分类问题。分类问题好理解,分类本身就是函数映射;回归问题一般都是在拟合一个趋势,所以回归问题也需要数据有标签,建模后映射。
无监督学习一般解决聚类问题。数据之间无标签,只靠数据间的内在相似度来聚类,一般用户画像都是通过无监督学习来完成。
半监督学习可以用来进行预测,但是模型首先要学习数据的内在结构以合理的组织数据来进行预测。
强化学习通过一系列的行动最大化“奖励函数”来学习模型,不管是好行为还是坏行为都可以帮助强化学习模型学习。强化学习中的教师角色(环境)不会告诉你往哪里改,只会告诉你做到对不对。
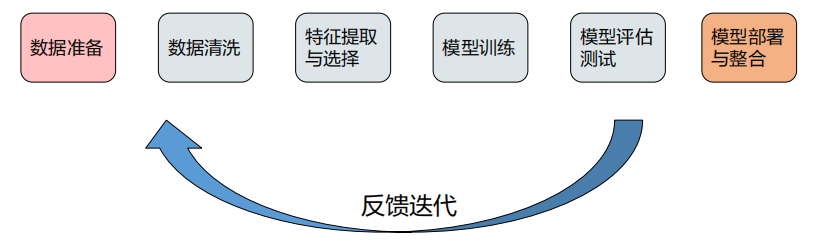
机器学习的整体流程
机器学习的整体流程有六步,其中重点在数据清洗、特征提取与选择、模型训练和模型评估测试这反复迭代的四步。
数据清洗
数据集是机器学习任务中的一组数据,其中每一个数据都称为一个样本。
数据集分为训练集和测试集。两者绝不可以有交集。因为,如果拿训练的数据测试会使得测试结果失真。
数据对于模型和项目是至关重要的,你的数据才最终决定了这个项目的好坏。所以,一定要对数据进行预处理。
数据预处理包括:数据清理、数据降维、数据标准化。
-数据清理:填充缺失值,发现并消除异常点。
-数据降维:简化数据属性,避免维度爆炸。
-数据标准化:标准化数据来减少噪声,以及提高模型准确性。
对数据进行初步的预处理后,需要将其转换为一种适合机器学习模型的表示形式。比如:在分类问题中,将类别数据编码成为对应的数值表示;对颗粒度大的数据分段划分减少维度;通过颜色空间、灰度化、几何变化、图像增强等处理图像数据。
特征选择
通常情况下,一个数据集当中存在很多种不同的特征,其中一些可能是多余的或者与我们要预测的值无关,此时我们要对清洗后的数据进行特征选择,特征选择的好处是:简化模型、减少训练时间、避免维度爆炸、避免过拟合、提升模型泛化性等。
特征选择的方法主要有:过滤法(Filter)、包装法(Wrapper)、嵌入法(Embedded)。
1、过滤法:利用统计学,计算特征与目标变量之间的相关性,来评估特征的重要程度,从而选择最佳特征子集。
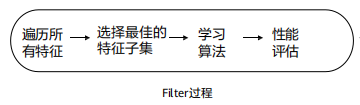
常用的过滤方法包括:
1.1、方差选择法:根据特征的方差选择特征。方差较小的特征往往包含的信息较少,可以设置一个阈值,选择方差大于该阈值的特征。
1.2、相关系数法:计算特征与目标变量之间的相关系数,选择与目标变量具有一定相关性的特征。
1.3、卡方检验:计算每个特征与目标变量之间的卡方值,选择卡方值较大的特征。卡方检验适用于特征与目标变量都是离散变量的情况。
1.4、互信息法:计算每个特征与目标变量之间的互信息量,选择互信息量较大的特征。互信息量反映了特征与目标变量之间的相关性,不论特征和目标变量是连续还是离散变量都适用。
1.5、L1 正则化:通过在目标函数中添加L1正则化项,促使模型选择更少的特征。L1正则化可以使一部分特征的系数变成0,从而实现特征选择的目的。
2、包装法:选择一个特征子集,利用分类器训练,根据分类器的性能(如准确率)来评价这个特征子集的好坏,最终选出最好的特征子集。其中分类器可以是任何机器学习算法,如决策树、支持向量机、逻辑回归等。
与嵌入法相比,Wrapper法能够提供更好的特征,因为Wrapper法考虑了特征之间的交互作用和相互依赖性,但是Wrapper法也更耗时,因为它要在不同的特征子集上运行机器学习算法来评估性能。
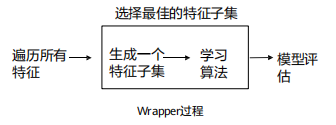
常用的包装法包括:
2.1、前向选择:从一个空的特征集开始。逐渐添加特征,直到达到预先定义的停止条件。
2.2、后向消元:从包含所有特征的特征集开始,逐渐删除特征,直到达到预先定义的停止条件。
2.3、递归特征消除:基于模型的系数或特征的重要性来逐渐删除特征,知道达到预先定义的停止条件。在每次迭代中,模型都会重新拟合并重新评估特征的重要性。
3、嵌入法:将特征选择嵌入到模型训练过程中,即在模型的训练过程中同时完成特征选择和模型训练。嵌入法使用不同的算法来进行特征选择,例如Lasso回归、Ridge回归、Elastic Net等,这些算法通过正则化来削弱模型中的不重要特征,进而达到特征选择的目的。
在使用Embedded进行特征选择时,一般将整个数据集划分为训练集和测试集。
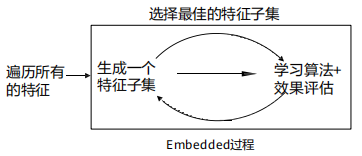
常见的嵌入法包括:
3.1、Lasso回归(L1正则化)
3.2、Ridge回归(L2正则化)
3.3、Elastic Net(L1和L2正则化的组合)
模型训练
我们以有监督学习为例,介绍接下来的机器学习流程。
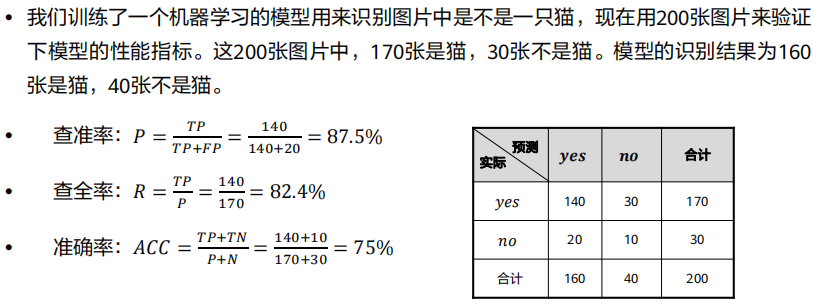
之后进入到学习阶段,这里举一个分类的训练案例:
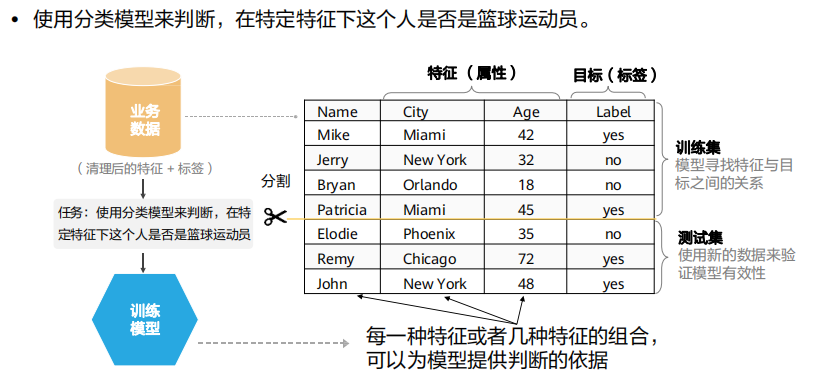
从图上可以读到,清理后的数据拥有特征和标签,而且被分为了训练集和测试集,我们的标签是目标值,通过特征来判断是什么标签。
学习完成后进入预测阶段:
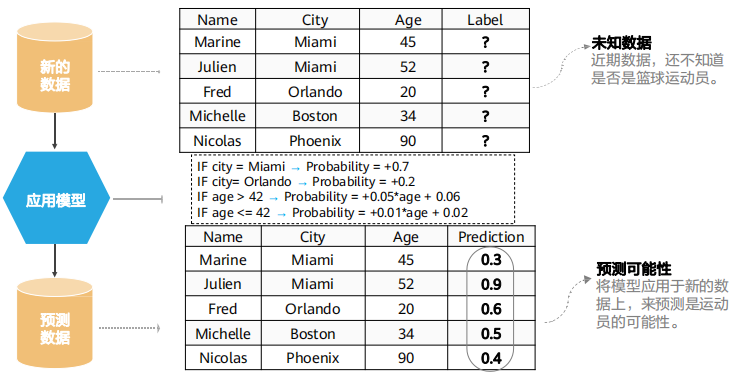
在预测中Label是未知的,根据学习到的模型,计算得到预测值。
模型评估测试
之后就该评价模型的好坏了,我们应该关注模型的泛化能力、可解释性、预测速率。
这里先解释一些名词。
泛化能力:也称鲁棒性,机器学习的目标是使得所学的模型能很好的应用于新样本,而不仅仅在训练样本上表现良好,模型适用于新样本的能力就是泛化能力。
误差:预测值与真实值之间的差距。误差分为训练误差和泛化误差,训练误差是模型在训练集上的误差,泛化误差是在新样本上的误差。
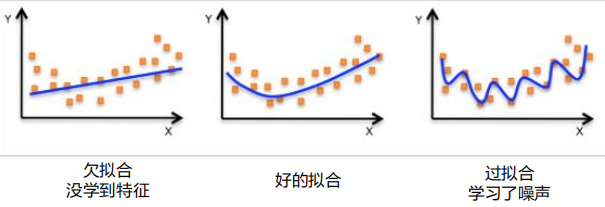
欠拟合:训练误差很大的现象。
过拟合:训练误差很小而泛化误差很大的情况。
模型的容量:指模型拟合各种函数的能力,也称模型的复杂度。容量和任务的复杂度和训练数据大小匹配时,算法效果最佳;容量不足时,可能出现欠拟合;容量高的模型能解决复杂的问题,但是过高时容易过拟合。
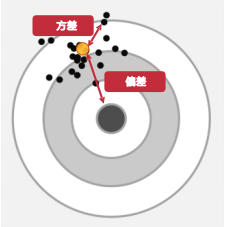
最终预测的误差=偏差²+方差+不可消解的误差。
-偏差是模型的平均预测值和目标值之间的差距;
-方差是模型的预测结果在均值附近的偏移幅度;
-不可消解的误差是实际上所有模型都是无限逼近而不是完全等同。
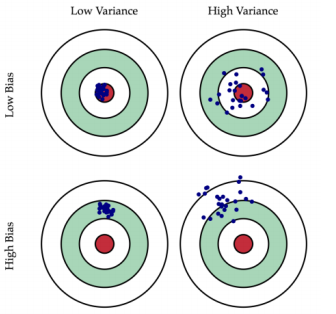
在实际问题中,我们会遇到不同的结果,有不同的方差和偏差的组合。
低偏差&低方差➜ 好模型;低偏差&高方差➜欠优模型;高偏差&低方差➜欠优模型;高偏差&高方差➜不良模型。
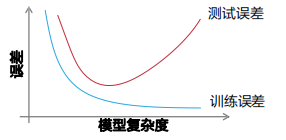
模型的复杂度(容量)与误差之间也有关系,随着模型复杂度上升的增加,训练误差会逐渐减小。同时,测试误差会随着复杂的增大而减小到某一点,继而反向增大,形成一条凸曲线。我们需要找到合适的复杂度(容量)来平衡测试误差和训练误差。
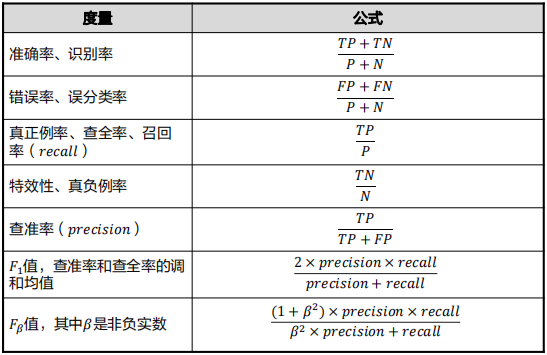
在机器学习的性能评估中,我们会用到大量的数理统计知识,以下是一些介绍。
MAE:平均绝对误差,越趋近于0表示模型越拟合训练数据。
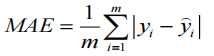
MSE:均方误差。
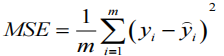
R²:取值范围[0,1],值越大表示模型越拟合训练数据,其中TSS表示样本之间的差异情况,RSS表示预测值与样本值之间的差异情况。y拔是样本均值,y尖是每一个预测值。
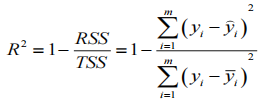
混淆矩阵:是一个为𝑚 × 𝑚的表(不一定是2×2)。
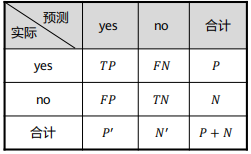
-P:正元组,感兴趣的主要类的元组,预测是yes的组。
-N:负元组,其他元组,预测是no的组。
-TP :真正例,被分类器正确分类的正元组,实际和预测都是yes的组。
-TN:真负例,被分类器正确分类的负元组,实际和预测都是no的组。
-FP:假正例,被错误地标记为正元组的负元组,实际no但预测yes的组。
-FN:假负例,被错误的标记为负元组的正元组,实际yes但预测no的组。
预测是yes第二位就是P,预测是no第二位就是N;预测和实际相同,第一位就是T,预测和实际不同,第一位就是F。
理想的,对于高准确率的分类器,大部分元组应该被混淆矩阵从(1,1)到(𝑚,𝑚)的对角线上的表目表示,而其他表目为0或者接近于0,即𝐹𝑃和𝐹𝑁接近0。