
人工智能入门13-华为昇腾实习笔记-python入门机器学习、环境配置、Jupyter Notebook
6.14学习:
- 观看《Python3入门机器学习 经典算法与应用 _课程 (imooc.com)》 1-3 课程所使用的技术栈
- 观看《Python3入门机器学习 经典算法与应用 _课程 (imooc.com)》 2-1 机器学习世界的数据
- 观看《Python3入门机器学习 经典算法与应用 _课程 (imooc.com)》 2-2 机器学习的主要任务
- 观看《Python3入门机器学习 经典算法与应用 _课程 (imooc.com)》 2-3 监督学习,非监督学习,半监督学习和强化学习
- 观看《Python3入门机器学习 经典算法与应用 _课程 (imooc.com)》 2-4 批量学习,在线学习,参数学习和非参数学习
- 观看《Python3入门机器学习 经典算法与应用 _课程 (imooc.com)》 2-5 和机器学习相关的“哲学”思考
- 观看《Python3入门机器学习 经典算法与应用 _课程 (imooc.com)》 2-7 课程使用环境搭建
- 观看《Python3入门机器学习 经典算法与应用 _课程 (imooc.com)》 3-1 Jupyter Notebook基础
- 观看《Python3入门机器学习 经典算法与应用 _课程 (imooc.com)》 3-2 Jupyter Notebook中的魔法命令
课程所使用的技术栈
课程环境
研究机器学习需要学习Python3的语法基础,框架主要是Scikit-learn,其他需要用到的是Numpy和Matplotlib,以及主要的IDE是Jupyter Notebook,这些环境都可以通过Anaconda来安装配置。
Scikit-learn:scikit-learn: machine learning in Python — scikit-learn 1.5.0 documentation是一个开源的机器学习库,提供了一系列用于数据挖掘和数据分析的工具。Scikit-learn建立在 NumPy 和 SciPy 上,包括了许多知名的机器学习算法,如支持向量机、随机森林、梯度提升等,并且提供了用于数据预处理、模型评估、模型选择和许多其他实用功能的工具。
Anaconda:是一个强大的包管理工具,极大的简化了数据科学的代码流程,使用户能够专注于数据分析和模型构建,不用花太多时间在管理环境和依赖上。Anaconda包括了Conda、Python以及超过1500个科学包及其依赖项,包括NumPy、Pandas、Matplotlib、SciPy和Scikit-learn等。Conda 是Anaconda的核心工具,是包和环境的管理器,允许用户安装、运行、更新库和应用程序,同时允许在不同的项目之间轻松的切换环境。此外,Anaconda还包括了Jupyter Notebook。Anaconda的安装过程非常简单,安装后,我们可以通过Anaconda Navigator这个图形界面来管理包和环境,或者使用命令行工具Conda进行更高级的操作。
课程数据集
课程所使用的数据集全部来自Scikit-learn内置的数据集或可以直接下载的数据集。
1、自带数据集sklearn.datasets.load_
鸢尾花数据集:load_iris():用于分类任务的数据集 |
2、可下载数据集sklearn.datasets.fetch_
MNIST数据集等 |
3、计算机生成的数据集sklearn.datasets.make_
make_blobs:多类单标签数据集,为每个类分配一个或多个正太分布的点集 |
机器学习世界的数据
以鸢尾花数据集 iris 为例,介绍机器学习数据的格式。

数据整体叫数据集 data set,每一行数据称为一个样本 sampel,(除最后一列)每一列都表达一个特征 feature,最后一列称作标记 label 。所有的特征合起来用 X 表示,X 是一个多维矩阵,标签用 y 表示,y 是一个向量。(用大写字母表示矩阵,小写字母表示向量)

在数学上通常把向量写成列向量,所以对于一行特征组成的特征向量(虽然看起来是一行,但出于线性代数的习惯,表达成列向量),我们通常采用转置的方法把特征向量拼接成整体的特征矩阵。

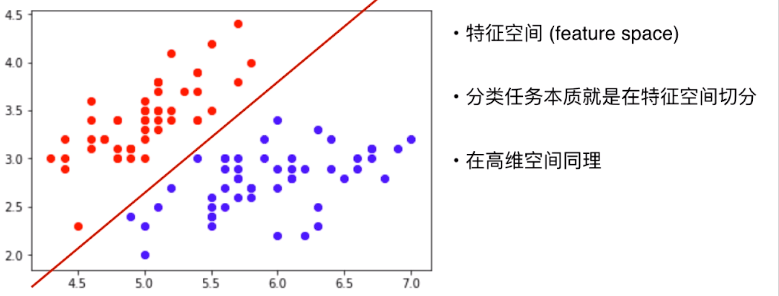
不同特征组成的空间叫特征空间 feature space,分类任务的本质就是在特征空间进行切分,切分可能是直线也可能很复杂。
很多时候在高维空间想问题不方便,就提取部分特征先在低维空间思考,之后把在低维空间中得到的结论推广到高维空间。
特征有些时候是有明显语义的,比如鸢尾花的四个特征。但很多时候特征又是很抽象的,比如在图像中,每一个像素点就是一个特征,颜色和深浅不同就代表不同的值。

机器学习的主要任务
机器学习可以解决的问题分为两类:分类和回归。
分类又分为:二分类、多分类(多分类任务可以转换成二分类任务,有一些算法天然支持多分类任务)、多标签分类(前沿)。
回归任务的特点是最终的结果是一个连续的数值,而不是离散的类别。在一些情况下,回归任务可简化成分类任务。
监督学习,非监督学习,半监督学习和强化学习
从机器学习算法的角度分类,机器学习可以分为:有监督学习、无监督学习、半监督学习、强化学习。
监督学习
监督学习是数据集有标签 Label,我们在这个课程中大部分都在学习监督学习。
具体监督学习可以看上一章节自己总结的内容。
非监督学习
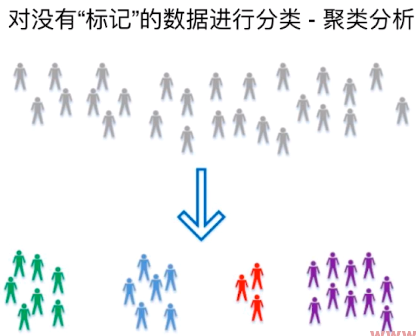
非监督学习是数据没有任何Label,对没有标记的一堆数据进行聚类分析。比如电商软件在用户浏览商品时,就是采用非监督学习来给用户贴标签。
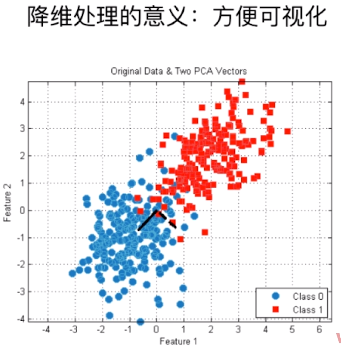
非监督学习还能完成的另一个重要功能是:对数据进行降维处理。对数据的降维处理主要包含两部分内容:特征提取和特征压缩。当我们面对非常高维的数据时,特征压缩就十分重要,其主要方法是PCA。而且数据降维处理还能把高纬的信息转化成可视的维度,方便我们可视化。

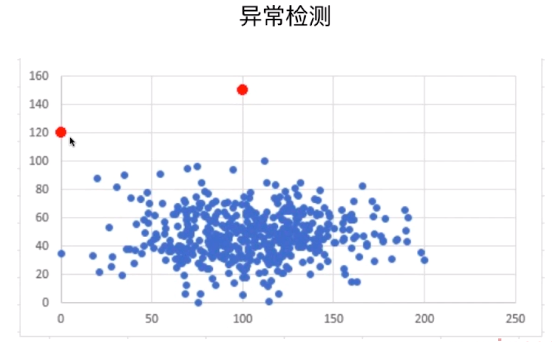
非监督学习还可以完成异常检测。
半监督学习
一部分有标记而另一部分没有,大部分来源于数据的标记缺失,这种情况在生活中更常见。
对于半监督学习通常先使用无监督学习的手段对数据做处理,使得数据都拥有Label,之后再采用监督学习手段对模型做训练和预测。
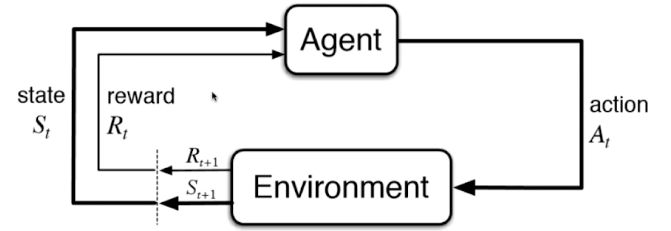
强化学习
此时算法要根据周围的环境来采取行动,之后根据行动的结果来得到反馈(奖励或者惩罚)。
批量学习,在线学习,参数学习和非参数学习
按照不同的角度,机器学习可以分为批量学习和在线学习或者参数学习和非参数学习,不过这样的分类并不常见。
批量学习在线学习
批量学习(离线学习)不考虑当算法投入使用后新的数据的优化问题。优点是简单,缺点是无法适应环境的变化。
在线学习每次输入样例后和输出结果对比,不断改进算法。优点是能及时变化,缺点是脏数据会影响系统的运行。
参数学习和非参数学习
参数学习的特点是,我们喂给机器学习很多数据,这些数据的让机器学习到了我们想要的参数(比如线性回归的w和b),一旦学习到了参数就不再需要原有的数据。
非参数学习是不对模型进行统计学上的假设,不对整个问题进行详细的建模,但在学习过程中依然有参数的参与。
和机器学习相关的“哲学”思考
经典算法所解决的问题通常是有固定、标准、唯一答案的问题,但机器学习不同,他面对的是高度不确定性的问题。面对这种问题,机器学习给我们的答案往往是不确定的、面对概率的、统计学的,我们难免会思考,这样的答案针对可靠吗?
2001年,微软的论文指出:当喂足够多的数据时,所有算法的准确率都在逐步的上升,而且当数据量大到一定程度时,算法的准确率差距并不大。
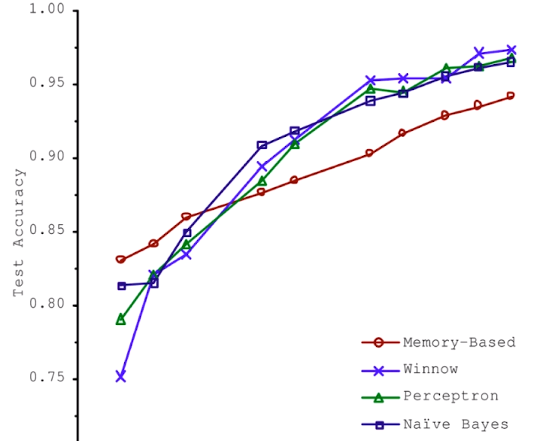
这说明在人工智能领域,算法本身并不是最重要的,重要的是数据(包括质量和数量)。
但是,最新的智能比如AlphaGo确提出:算法也是十分重要的,因为他并不需要任何数据。也许是围棋具有特殊性,现阶段,数据依然是最重要的。
脱离具体问题,谈哪个算法好是没有意义的。
在面对一个具体问题的时候,尝试使用更多的算法进行对比试验是十分必要的。
课程使用环境搭建
下载安装Anaconda-python3.7的版本Download Anaconda Distribution | Anaconda。
教程anaconda的安装和使用(管理python环境看这一篇就够了)-CSDN博客。
查看现在安装的组件。
查看现在电脑中的python环境。
我们可以直接lunch到jupyter notebook。
有些算法需要底层的编程,对于一些代码可以使用一般的IDE:Pycharm写成.py文件,然后在jupyter notebook中进行调用,Pycharm下载社区版就够用了。
在进入Pycharm新建项目时,需要选择对应的python解释器的版本,此时要选择Anaconda下的Python解释器。
在里面新建一个名为First的Python文件,首先测试我们在这一系列课程中使用的Python包是否可用。
import numpy |
点击运行,控制台看到输出”Hello,Machine Learning!”即可。
课程所有代码都在老师的Github上有:GitHub - liuyubobobo/Play-with-Machine-Learning-Algorithms: Code of my MOOC Course 。
Jupyter Notebook中的魔法命令
%run
# %run |
用刚刚的python文件,代码改成如下,运行后保存,可以看到输出了”Hello,Machine Learning!”。
import numpy |
在这个文件的目录中用cmd运行jupyter notebook,新建一个notebook,输入如下代码,可以看到也输出了”Hello,Machine Learning!”。(注意采用相对路径)
%run First.py |
然后测试调用First.py中的函数,输入以下代码然后运行。
hello("Xiao Wang") |
可以看到输出了”Hello Xiao Wang !”。
打包函数库
将自己写的算法打包成一个模块,在jupyter notebook加载这个模块。
用Pycharm新建一个文件夹mymodule,在文件夹中新建Predict.py,test.py的内容如下。
def predict(x): |
为了让这个文件夹中所有python脚本形成一个模块,我们再在这个文件夹中新建__init__.py,这就是最简单的让文件夹成为模块的方式。
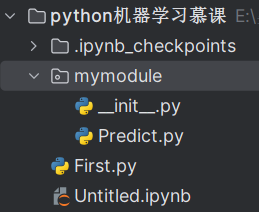
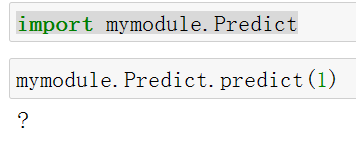
此时在mymodule文件夹所在的目录下打开jupyter notebook,只要输入import mymodule.Predict即可导入这个包,输入以下代码测试,看到输出了一个”?”。
import mymodule.Predict |
%timeit
# %timeit |
在jupyter notebook中输入以下代码,测试timeit的效果。
%timeit L = [i**2 for i in range(1000)] |
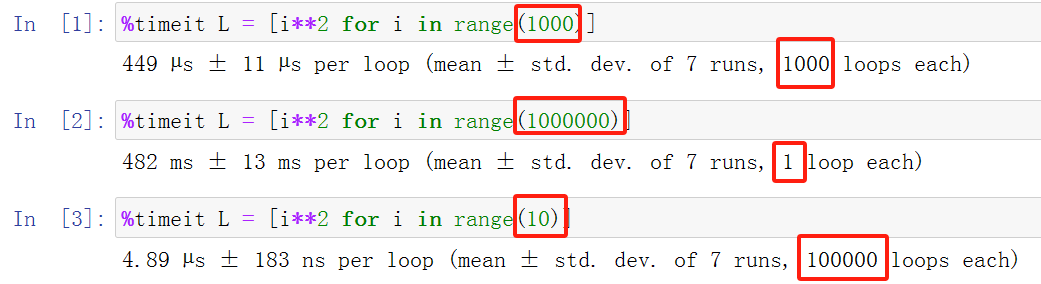
%%timeit |
%time
# %time |
%time L = [i**2 for i in range(1000)] |
一般会返回CPU time和Wall time,CPU time是多个核运行时间相加的结果,Wall time是现实世界中的时间,如果是多线程Wall time往往会小于CPU time。










